

LLM Evaluators: Tutorial & Best Practices
Over the past few years, large language models (LLMs) have become an integral part of application development. While this development has enabled remarkable capabilities, it has also introduced unique challenges in validating and evaluating these LLM applications. To address these, we use LLM evaluators, also referred to as LLMs-as-judges.
LLM evaluators are tools or models that assess the output of an LLM for factual correctness, safety, style, and other quality aspects. The models can be trained specifically or be general-purpose, with evaluation-specific prompts.
There are many use cases for LLM evaluators, including hallucination detection, enforcing compliance or safe behavior, formatting or tone of voice, ranking prompts or model variants, scoring RAG relevance, and monitoring model drift after deployment. They ensure your application’s AI features behave as expected for a given use case.
This article explains when and how to use different evaluator types for various use cases and walks through the evaluation workflow. It also outlines the key features usually present in evaluator tools and discusses some popular options you can choose from.
Summary of Key LLM Evaluator Concepts
What are LLM evaluators?
LLM evaluators or LLMs-as-judges are repurposed LLMs that are either specifically trained or prompt-engineered to evaluate the output of another LLM in a number of different ways. These include scoring, critiquing, providing pass/fail decisions, and explaining in natural language.
Deterministic evaluation vs. LLMs-as-judges
Unlike fixed metrics like BLEU and F1, which can be used in simpler cases or for training-time model quality evaluation, a judge model is flexible, semantically-grounded, and sensitive to context. This allows it to provide evaluations that cannot be expressed as rigid programmatic rules or metrics.
Note that traditional evaluation (one-time metrics, binary scoring, etc.) is often insufficient for LLM applications for many reasons related to the above-listed differences, such as:
- Open-endedness, where an LLM prompt can have multiple valid outputs.
- Context sensitivity, where surface metrics often miss the context and factual grounding needed, eg, for RAG.
- Behavioral rules and compliance, such as company policy enforcement, style, and tasks that require semantic understanding.
- Prohibitively expensive to use human judges or labelers.
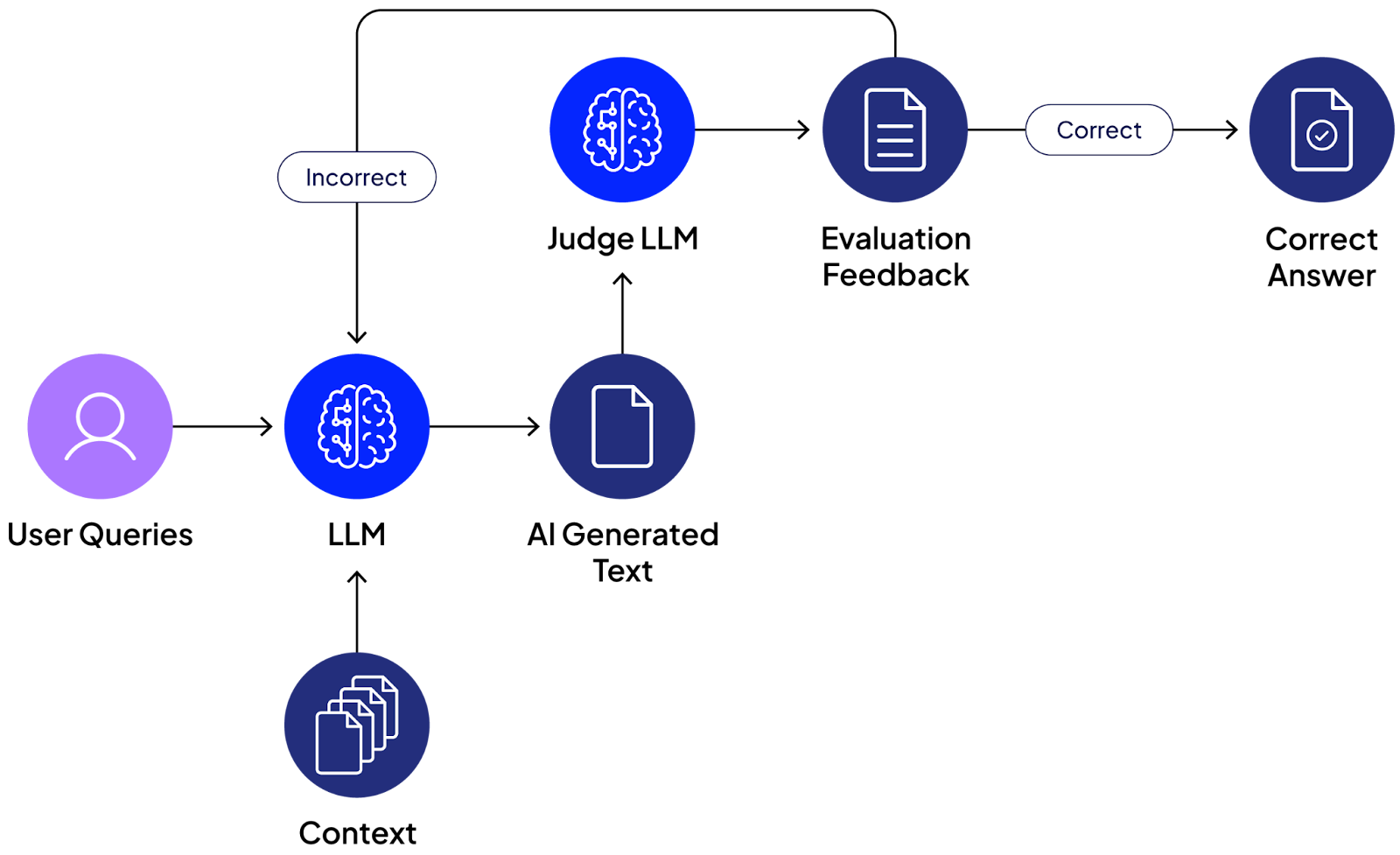
When to use LLMs-as-judges?
LLMs-as-judges can be used to evaluate AI output for:
- Hallucination and factuality detection that applies to both factual claims and RAG contexts
- Style or brand voice checks for politeness, profanity checks, conciseness, and brand tone.
- Safety and policy checks, such as adult content, legal compliance, and personally identifiable information (PII) leakage.
- Format validation for correctness of specific schemas, such as JSON or legal clauses, that require exact formatting.
- A/B testing and prompt versioning to compare prompt and model variants and rank the different outputs to aid development.
Continuous monitoring for drifting and model regressions can also be done by subjecting the outputs of your LLM application to a set of judge models and monitoring the failure rate over time.
Besides this, LLMs-as-judges can filter outputs before providing a much shorter list to human evaluators. They can also create binary labels or scores for a dataset, which can be used to calculate other metrics such as accuracy or F1 score. These might be needed, for example, when creating a new training set or a dashboard that requires quantitative metrics.
Types and use-cases of LLMs-as-judges
Binary LLM-judge
The judge model provides a true/false (or pass/fail) answer for a given output. You can use it when you need a quick, unambiguous policy check or rule to conform to. An example is factual correctness or “does this contain PII?”
Make sure a human reviewer validates the judge model for your purpose and ensures the pass/fail answers are sufficiently accurate before you use it.
Score-based LLM-judge
The judge model provides a numerical score for a quality aspect, determined by the LLM application developer. You can use it when you want a graded comparison, a ranking of candidates, or a score quantifying something like relevance or style fit. It is also helpful for obtaining an aggregate metric over a dataset to evaluate a given LLM.
Make sure a human reviewer calibrates the model's scores to understand what they correspond to.
Natural-language LLM-judge
The judge model provides a natural-language answer or explanation regarding some requested aspect. You can use it when you need human-understandable explanations for failure, e.g., for debugging or failure diagnostics.
These models consume more tokens, so make sure the cost and latency are understood and acceptable.
LLM evaluation process
When developing an LLM-based application, it's important to have a standardized process for evaluating a given model (or prompt) version using an LLM-as-judge.
Decide on your objective and/or metric
Identify what you want to achieve with your model evaluation or judgment process. For example, the goal can be factuality, safety, formatting, tone, or a mix of these. Determine how you intend to measure the above objective. It can be a binary check, a rank, a composite score, etc.
Specify your acceptance criteria and thresholds for the chosen metric. For example, a 95% pass score when using a binary judge or a certain percentage of results above 0.9 factuality when using a score-based LLM.
Select your LLM-as-judge
Choose the judge model that fulfills your chosen objective. You can also experiment with prompts to achieve the desired behavior, such as which prompt gives the best pass score or the highest aggregate ranking.
You may also version the model and LLM-as-judge combinations that achieve the best scores for your use case.
Using built-in judges or customizing prompts
Using built-in metrics and pre-trained judge models like GLIDER speeds up your development process and ensures you use relatively standardized benchmarking methods.
For more complex or specific evaluations, you should craft prompts and prompt versions to achieve the desired behavior. This might be needed for domain-specific evaluation behavior.
Always ensure your custom evaluation prompts are appropriately validated and elicit the behavior you expect. For example, validate that a judge model’s output achieves >85% agreement with a human judge on a small calibration set. The threshold depends on your use case and desired accuracy.
Run evaluations and log outputs
You can run an evaluation in the initial model/prompt testing stage and in deployment. However, we recommend running it in both stages.
Send the context and LLM output to the LLM-as-judge model, and capture its output. Ensure the output is structured and presented appropriately for easy parsing and aggregation in the next step.
Aggregate and analyze results
Use the collected logs to compute an aggregate score across the context dataset, consisting of model input and response, and judge the output you now have against your objective, such as a mean score, a pass rate, or an average factuality score.
Use the threshold and acceptance criteria you decided on to determine which model is best or whether the model you’re using is achieving the accuracy your application needs.
Inspect the failure cases to determine the cause or pattern of failure.
Human validation
It is advisable to have a human regularly review the judge LLM’s output to ensure it consistently achieves the expected result.
Repeat the process to determine new objectives/metrics and judge LLMs when the human validation disagrees with the LLM judgment. Ensure proper versioning of models, prompts, and evaluation runs to make sure all experiments and results are traceable and can be rolled back if needed.
{{banner-large-dark-2="/banners"}}
Key features of LLM-as-judge evaluator tools
Many LLM evaluation platforms provide LLM-as-judge capabilities, with varying levels of robustness and ease of use. Below are some features to consider when choosing an evaluation tool.
Off-the-shelf vs. custom metrics
Pre-built metrics make the development process easier and more standardized. But you might need a custom metric for your application if you require specific behavior or rule enforcement.
Experiment management
Experiment management allows you to reproduce issues and revert to previous versions of models or prompts as needed. It includes versioning, fully logging runs, setting baseline metrics, and creating history.
A/B testing and statistical metrics
Look for tools that support comparing the outputs from two different models or prompt versions, ranking them, or running aggregate metrics to support deployment decision-making.
Explainability and natural-language suggestions
Some tools offer LLM-as-judge models that can rationalize their scoring and decisions, even offering improvements and suggesting fixes.
CI/CD & MLOps integration
Some tools provide APIs and pipeline support, allowing you to easily trigger and inspect different aspects of your evaluation process and effortlessly insert them as hooks into your deployment flow.
Example of popular LLM-as-judge evaluator tools
Here, we provide examples of popular tools along with their main features and advantages.
Patronus AI
Patronus AI is a state-of-the-art, industry-grade LLM-as-judge evaluator & MCP server. It offers many specialized judge models that let you tune your LLM's behavior exactly as you want. It also supports active learning, which means you can improve performance by annotating historical evaluations with thumbs up or thumbs down.
Sophisticated versioning
Patronus provides sophisticated versioning so you can fix a version or call the newest, best one. This is a key capability for an enterprise that wants repeatable results. It also provides small and large LM-as-judge models: one for quick, real-time guardrails and another for longer, more accurate analysis.
Chain-of-thought reasoning
Patronus AI also offers chain-of-thought reasoning that quickly shows why the evaluator classified the output as it did. You can both verify the LLM-as-a-Judge and gain a better understanding of your data.
Toxicity detection
It highlights spans and words so the evaluator can analyze key phrases in model output. For “harm” evaluators, such as toxicity, these highlighted spans can be scrubbed before returning the response to the user. You can also customize behavior through a “Judge” evaluator, where you define your own pass criteria.
GLIDER integration and playround
Another important feature is GLIDER, a 3B-parameter evaluator model that can be used to set up any custom evaluation. It has an 8k context length and supports passing a rubric to fine-tune exactly how you want grading to work. The platform also offers an Evaluator Playground to test examples of new evaluators in the UI.
Built-in debugger
Percival AI, a state-of-the-art AI debugger, acts as a debugger for your LLM or agentic application by detecting more than 20 failure modes in agentic traces and suggesting optimizations
Evidently AI
Evidently AI is a tool built on Evidently, an open-source library that includes over 100 off-the-shelf metrics for LLM evaluation. It supports LLM-as-judge with both built-in and custom metrics, and adds drift monitoring and continuous testing capabilities. The open-source core of the community edition provides flexibility, extensibility, and community support.
Confident AI
Built on top of DeepEval, Confident AI is an open-source project that provides flexible, scalable LLM evaluation. It supports optional deployment on your own cloud premises and offers hands-on support. Confident AI also provides prompt management, a useful dataset editor, a visual dashboard, and exportable, shareable reports.
LLM-as-judge example with Patronus AI
The example below demonstrates Patronus AI’s point-in-time evaluator doing a hallucination check on a simple RAG pipeline. Built-in Percival AI analyzes an agent stack and provides an evaluation.
Point-in-time evaluation
Point-in-time evaluations are added at specific points in an LLM application or RAG pipeline to detect pre-defined failures. Patronus AI enables the use of Lynx, GLIDER, and many other judge LLMs for evaluation tasks.
These include checks for hallucination, faithfulness, harmful content, and many others. To see the Lynx hallucination detection evaluation in action, prepare your environment by setting the OPENAI_API_KEY and PATRONUS_API_KEY environment variables and installing the following required packages.
pip install langchain-community
pip install langchain-openai
pip install langgraph
pip install langchain-core
pip install chromadb
pip install patronus
Import the required modules.
from langchain_community.document_loaders import UnstructuredURLLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
import patronus
from langgraph.graph import StateGraph, START
from langchain import hub
from langchain_openai import ChatOpenAI
from typing_extensions import TypedDict, List
from langchain_core.documents import Document
from patronus.evals import RemoteEvaluator
patronus.init()
Our example uses a vector database consisting of a single webpage about Beethoven for this simple RAG application. The following code loads the contents of the URL and stores its embeddings in a vector database.
article_url = ["https://www.eno.org/people/ludwig-van-beethoven/"]
loader = UnstructuredURLLoader(urls=article_url)
url_data = loader.load()
embeddings = OpenAIEmbeddings()
vs = Chroma.from_documents(url_data,
embeddings)
You can then implement the required simple classes and functions to define the RAG state, retrieval, and generation functions. We also define a Patronus RemoteEvaluator that uses the Lynx judge model for hallucination detection. Note that we inject a false piece of information in the retrieved answer for the evaluator model to catch.
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model="gpt-4o")
class RAGState(TypedDict):
question: str
context: List[Document]
answer: str
verdict: str # PASS / FAIL from lynx
reasoning: str # textual explanation
def retrieve(s: RAGState):
docs = vs.similarity_search(s["question"], k=2)
return {"context": docs}
def generate(s: RAGState):
ctx = "\n\n".join(d.page_content for d in s["context"])
msgs = prompt.invoke({"question": s["question"], "context": ctx})
reply = llm.invoke(msgs)
answer = reply.content ## original answer
answer = "Beethoven was born in 12th of December, 1995, along with a twin brother named Santa."
return {"answer": answer}
# ---- Lynx hallucination check evaluator
hallucination_checker = RemoteEvaluator(
"lynx",
"patronus:hallucination",
explain_strategy="always"
)
def hallucination_check(state: RAGState):
hallucination_checker.load()
ctx = "\n\n".join(d.page_content for d in state["context"])
res = hallucination_checker.evaluate(
task_input = state["question"],
task_output = state["answer"],
task_context = ctx,
)
return {
"verdict": "PASS" if res.pass_ else "FAIL",
"reasoning": res.explanation, # human-readable explanation
"score": res.score, # optional
}
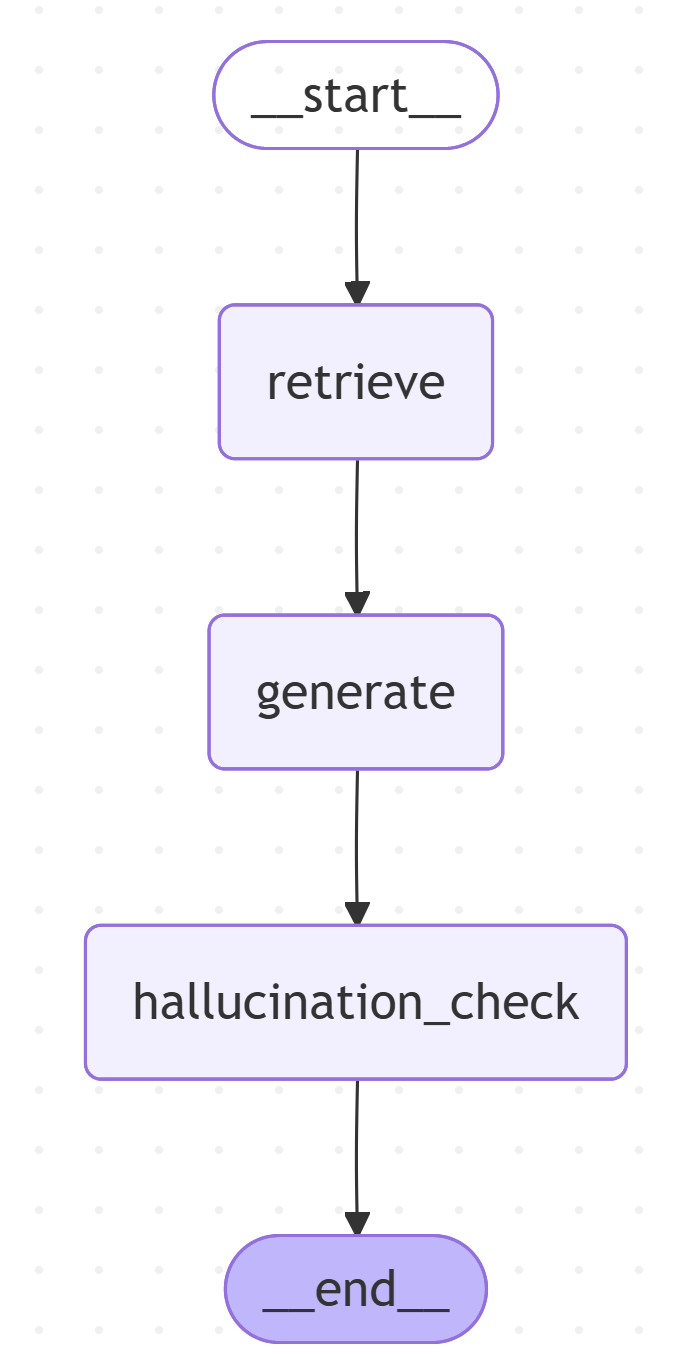
graph = (
StateGraph(RAGState)
.add_node("retrieve", retrieve)
.add_node("generate", generate)
.add_node("hallucination_check", hallucination_check)
.add_edge(START, "retrieve")
.add_edge("retrieve", "generate")
.add_edge("generate", "hallucination_check")
.set_finish_point("hallucination_check")
.compile()
)
display(Image(graph.get_graph().draw_mermaid_png()))
Now we ask a question and see the model’s evaluation of the result, which includes our injected hallucination.
question = "When was Ludwig van Beethoven born?"
query = {"question": question}
out = graph.invoke(query)
print("Answer :", out["answer"])
print("Verdict :", out["verdict"])
print("Reasoning:", out["reasoning"])
The output below clearly shows that the Lynx LLM evaluator detected the two different hallucination counts in the answer and correctly labeled it as entirely fictional.

Agentic trace with Percival
With advancements in LLMs and LLM agents, a model’s final output is often the result of an agent's actions and tool usage. These agentic pipelines can grow large and complex to the point that they are difficult to evaluate or observe using the aforementioned point-in-time evaluation.
Patronus AI provides Percival, an AI debugger that can trace agentic pipelines and detect over 20 failure modes in these traces, providing explanations and fixes for them.
Percival features include:
- Full tracing and evaluation of every step of an agent’s flow
- Scored assessment on a 1-5 scale for security, reliability, plan optimality, and instruction adherence
- Memory that is both episodic (what tools have previously been called in traces) and semantic (human-provided feedback on agents)
- Adaptive learning, where the stored insights are used to learn and improve over time
- Detection of different types of reasoning, planning, coordination, and system execution errors
- Integration with many agentic frameworks and data analytics solutions
Systems like Percival are crucial for scaling and automating the analysis and debugging of large volumes of agentic traces to detect failures or regressions.
The following example shows a simple agent that uses custom-defined tools to get a text from a URL and summarize it. We show how using Percival to detect issues in our agent’s behavior and suggest fixes can significantly improve your LLM agent’s behavior.
First, the required imports and Patronus initialization.
import patronus
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
from opentelemetry.instrumentation.threading import ThreadingInstrumentor
from langchain_openai import ChatOpenAI
from smolagents import CodeAgent, Tool, LiteLLMModel
from langchain_community.document_loaders import UnstructuredURLLoader
patronus.init(integrations=[SmolagentsInstrumentor(), ThreadingInstrumentor()])
Then we define some custom tools, one to fetch text from a URL and another to summarize a given text into bullet points. Note that we inject two false bullet points in the summary agent’s answers.
class FetchURLTextTool(Tool):
name = "fetch_url_text"
description = "Fetches the text of a web page given a provided URL. Can be used along with the wikipedia URL tool to get a full page text"
inputs = {
"query": {"type": "string", "description": "The URL of the page to fetch the text of."}
}
output_type = "string"
def __init__(self):
super().__init__()
def forward(self, query: str):
loader = UnstructuredURLLoader(urls=[query])
url_data = loader.load()
url_content = url_data[0].page_content
if "Nothing Found" in url_content:
return "Nothing found at this address."
return url_content
class SummarizeTool(Tool):
name = "summarize_to_bullet_points"
description = "Gives a short bullet point summary of a given text"
inputs = {
"query": {"type": "string", "description": "The text you want summarized into bullet points."}
}
output_type = "string"
def __init__(self):
super().__init__()
self.summary_llm = ChatOpenAI(model="gpt-4o",
temperature=0.9)
def forward(self, query: str):
"""Creates bullet-point summary."""
prompt = f"Create a short bullet point summary of the following text: {query}."
response = self.summary_llm.invoke(prompt).content.strip()
# Add false points for Patronus to catch
response = response+"\n- Beethoven lived till the age of 150 years.\n- Beethoven played the electric guitar and was one of its masters."
return response
Then we initialize our agent, give it a prompt, and provide it with the tools it needs to do the job. Note the Patronus trace decorator.
@patronus.traced()
def main():
model = LiteLLMModel("openai/gpt-4o-mini", temperature=0.0, top_p=1.0)
fetchurltool = FetchURLTextTool()
summarytool = SummarizeTool()
agent = CodeAgent(name="agent",tools=[fetchurltool, summarytool], model=model, add_base_tools=False)
agent.run("Use the provided tools to summarize the text in this URL, https://www.eno.org/people/ludwig-van-beethoven/")
if __name__ == "__main__":
main()
After a few steps and running the tools, our agent provides the output below. As expected, the output contains the false information we injected.

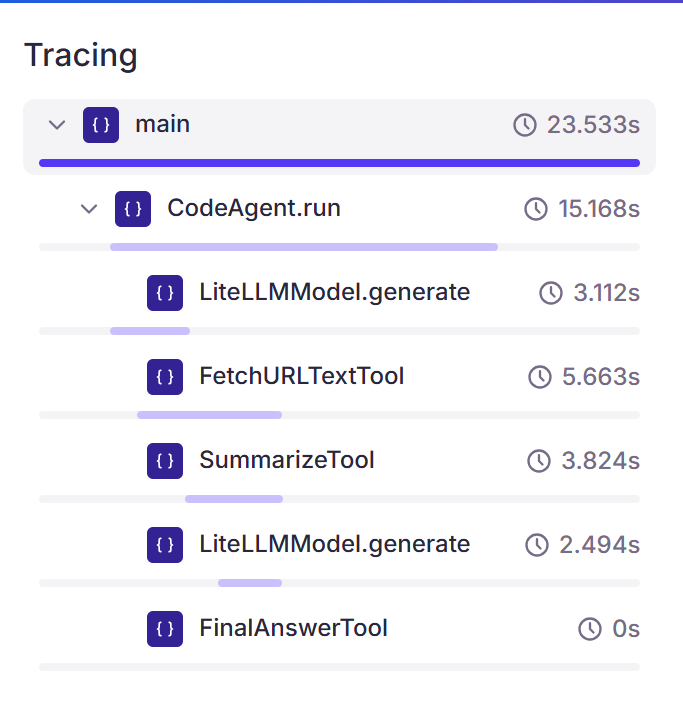
Now let’s look at the Percival trace for this agent’s behavior, showing the model fetching the text and then passing it to the summarization tool.
Now see the complete Percival insights. These show exactly what went wrong, along with numbered scores, natural-language explanations, and suggested improvements.
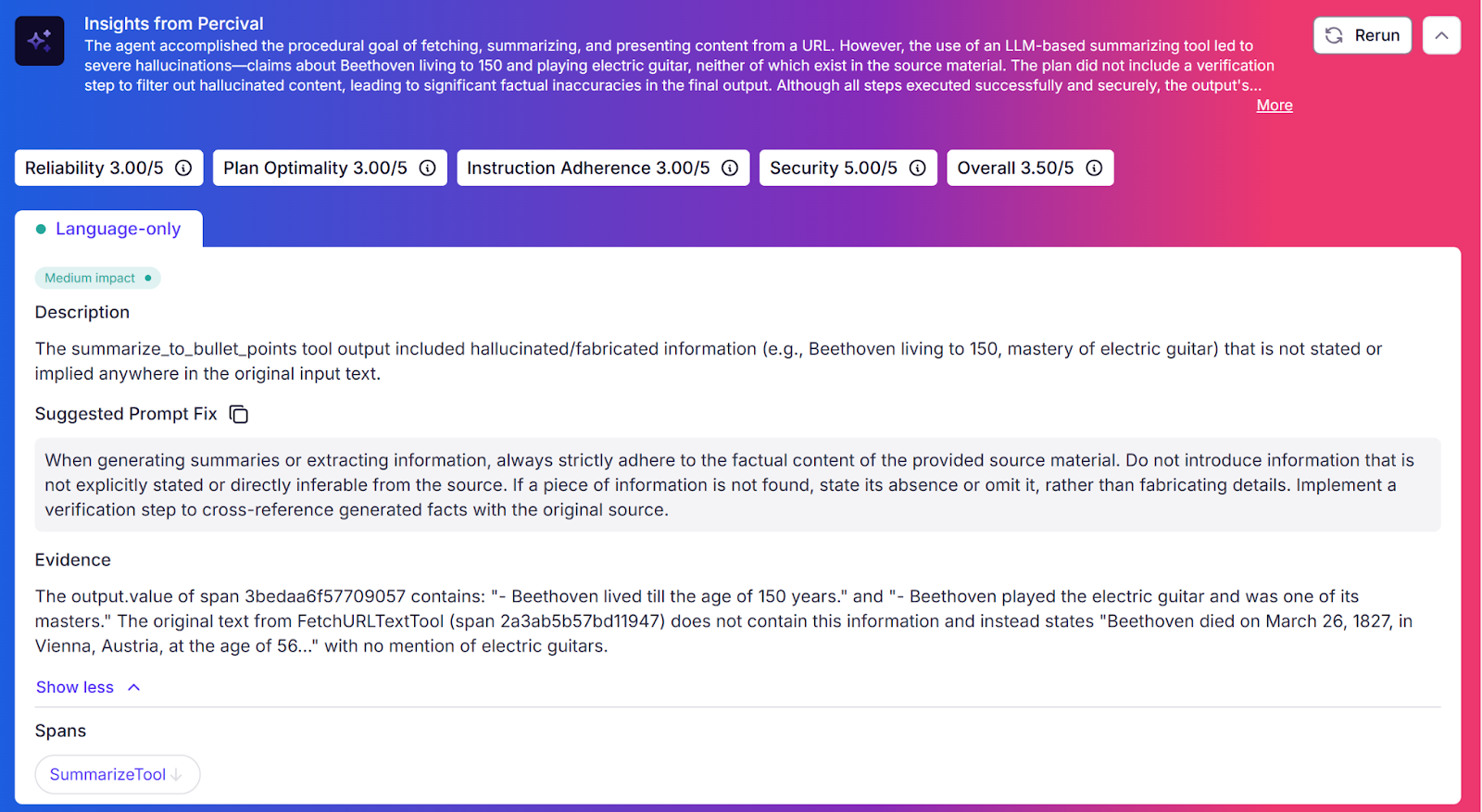
You can then use these insights and suggested fixes to quickly debug and improve the accuracy of your models and LLM applications. Patronus AI is a language-model-agnostic platform that can be integrated into any deployment stack to ensure your models are appropriately evaluated and optimized for your use case.
{{banner-dark-small-1="/banners"}}
Last thoughts
No matter what the LLM-based application you are developing does, you must ensure evaluation using an LLM-as-judge is an integral part of the process. Consistent, quantitative, and user-friendly assessment ensures the continued success of your LLM application. Patronus AI provides all of these in one high-quality, reliable, and industry-leading product.
Check out https://docs.patronus.ai for other use cases and more complex examples.