%201.avif)



Customer Service
Previously, the Patronus AI platform has supported companies in evaluating their customer service chatbots on quality, context retrieval, hallucination, summarization, and safety to ensure end-to-end success.

Areas of Experience
We have experience evaluating support responses to prevent hallucinations, tone, guardrails, and assumptions
Algomo
Preventing Hallucinations in AI-Powered Customer Support Chatbots with Lynx
Hospitable.com
Evaluating and Optimizing Personalized Message Replies for Airbnb Hosts
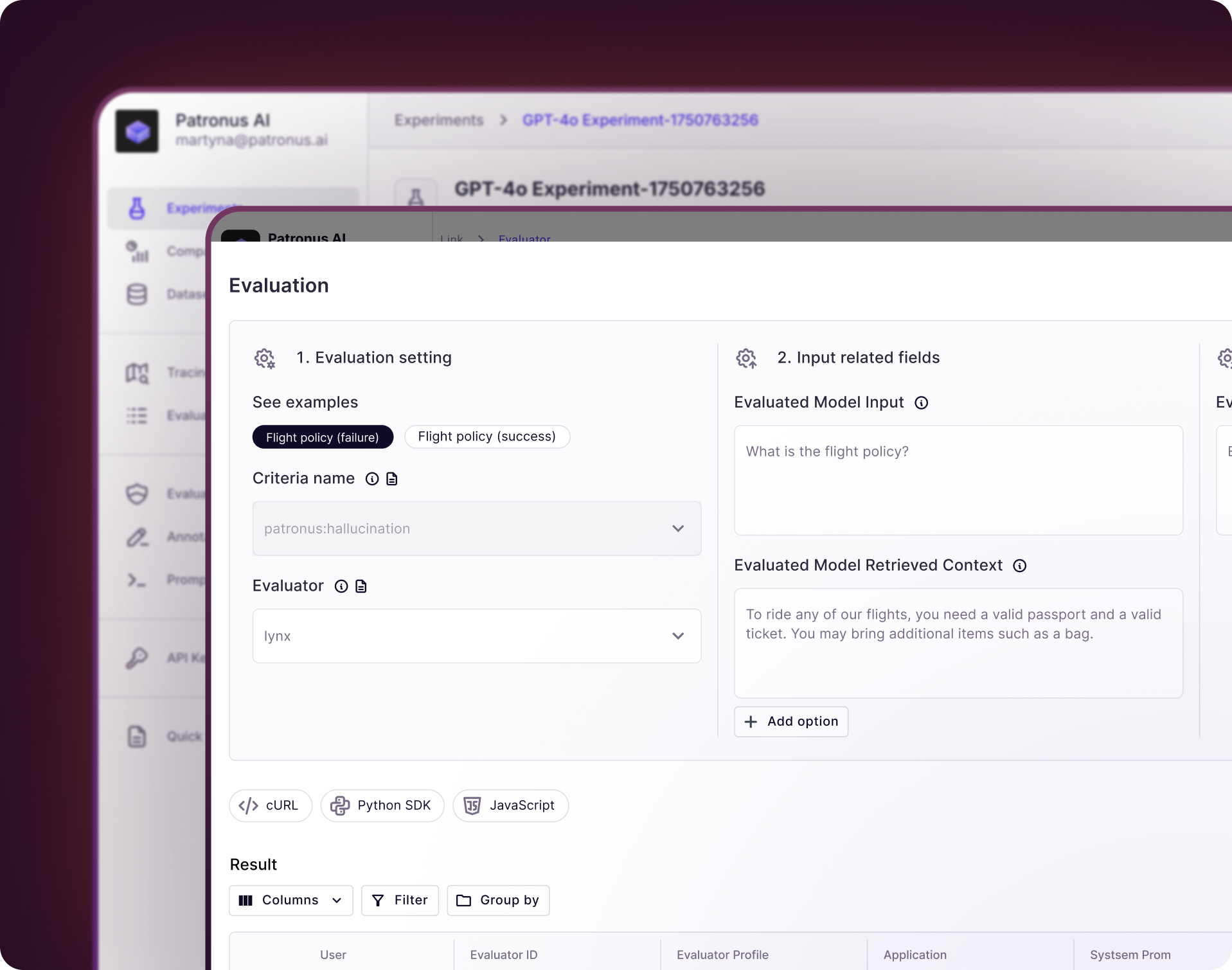
What is our Customer Service Evaluation?
As a part of this release, customers can now evaluate their LLM system against FinanceBench on the Patronus AI platform. The platform can also detect hallucinations and other unexpected LLM behavior on financial questions in a scalable way.
What We Evaluate
Accuracy
Providing accurate, correct information via recall
Relevance
Ensuring that the output is contextually relevant to the question.
Behavior Alignment
Adhering to company policies, understanding restricted topics, and maintaining tone control when producing outputs.
Safety
Mitigating risks from prompt injections, data leakage, toxicity, and bias when responding.
Multimodal
Testing for proper speech recognition and intent classification when parsing user input.
Multi-step
Evaluating appropriate planning, delegation, and execution behaviors required for task completion.
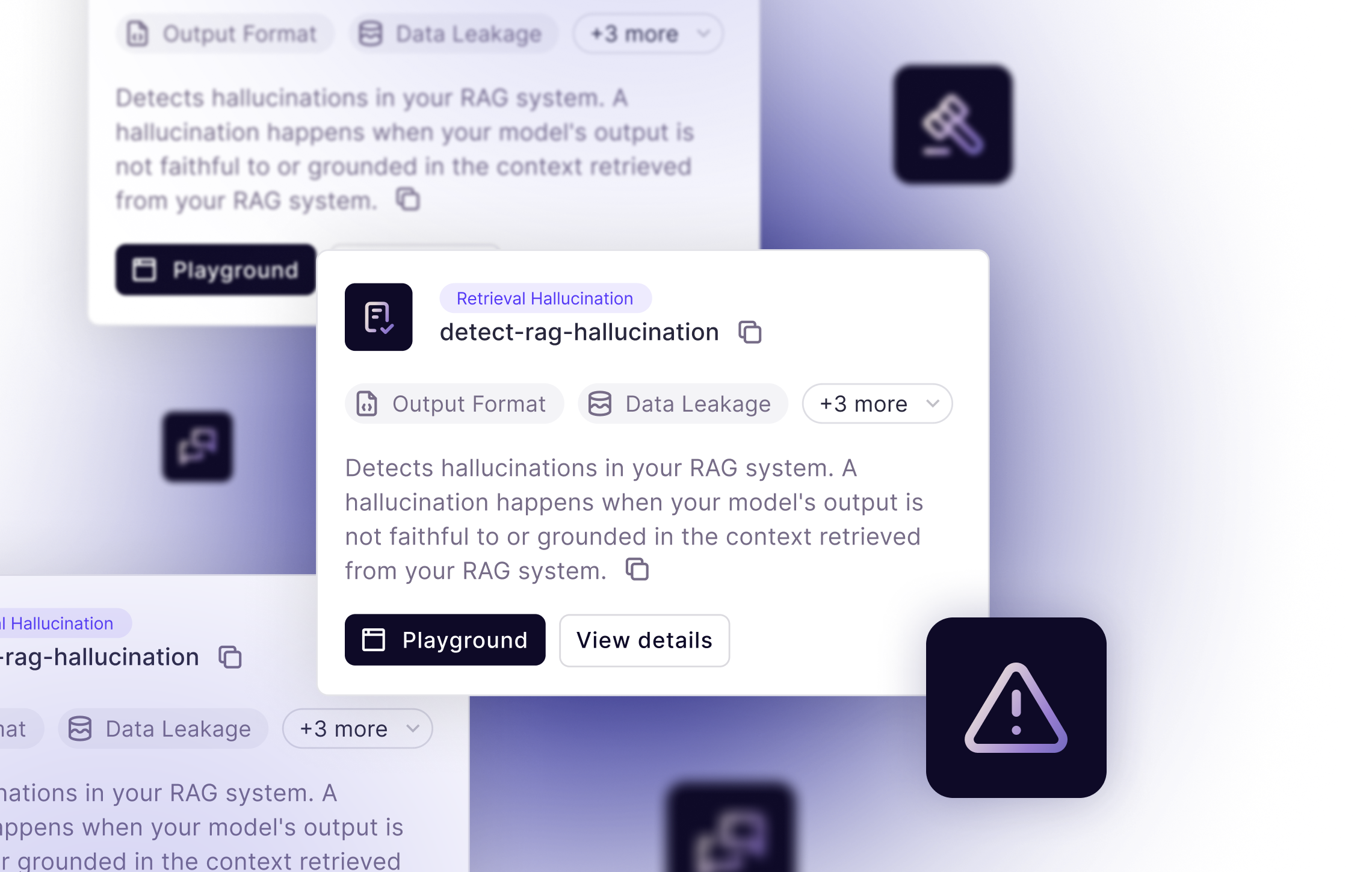
Standard Product
Current platform offerings, such as evaluators, experiments, logs, and traces to get you up and running immediately
Custom Product
Collaborate on the creation of industry-grade guardrails (LLM-as-a Judge), benchmarks, or RL environments to evaluate with more granularity


