

Custom Optimization Tools for LLM: Best Practices and Comparison
Large language models (LLMs) are increasingly becoming an integral part of application development, with a growing number of tools available to optimize and/or customize LLMs for the particular application or service you are developing.
These tools—and the concept of LLM optimization itself—cover a wide range of use cases and stages in the development and deployment process of LLM-based applications. Their roles include providing an orchestration framework to manage your LLMs to data annotation, prompt versioning and engineering, and LLM evaluation.
This article provides an overview of these different concepts and some of the available tools you can use to optimize LLMs to suit your unique needs.
Summary of key categories of LLM custom optimization tools
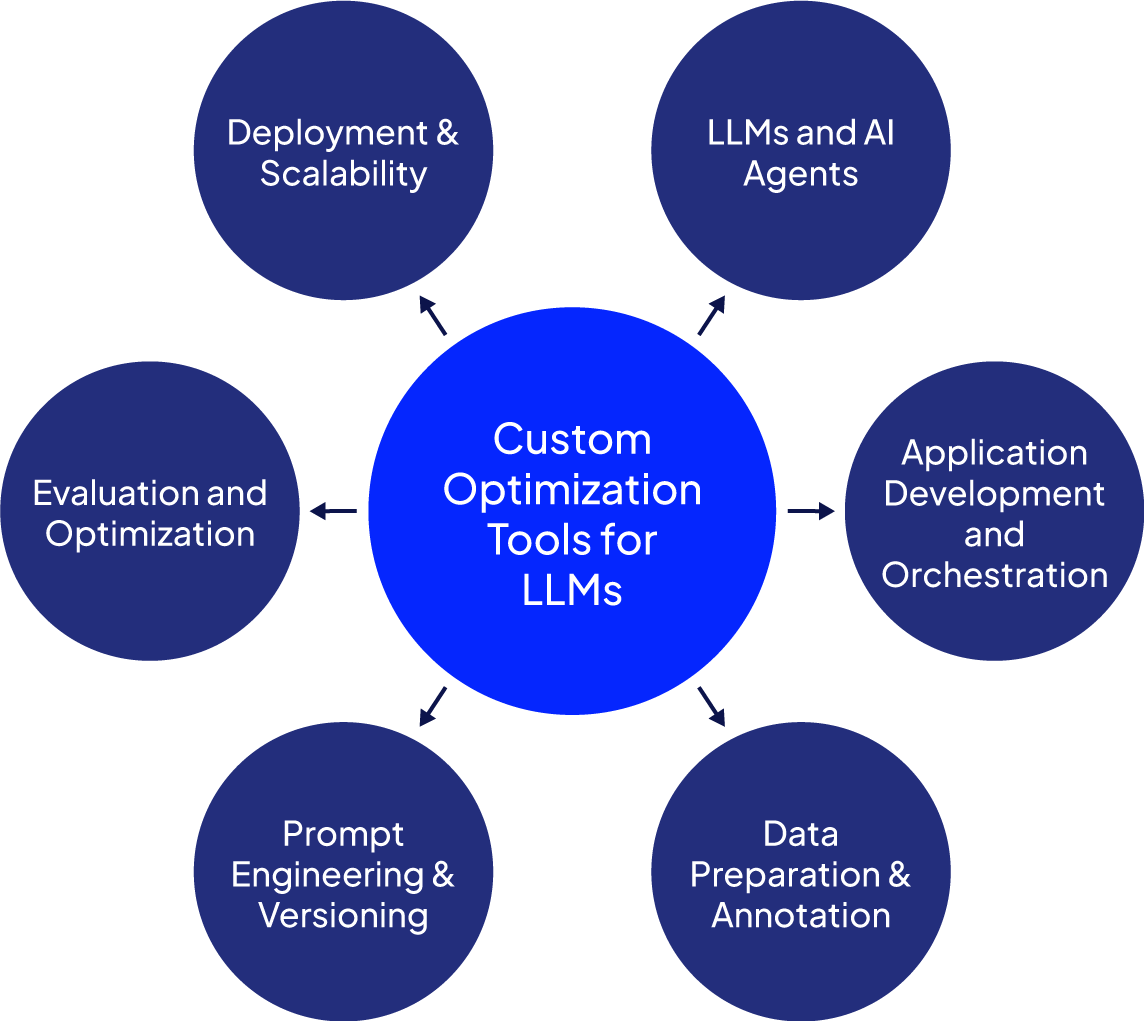
Determining whether your LLM is fit for purpose
The first decision you will want to consider is, naturally, which LLM to use. There are different categories from which to choose, and the final decision depends on your use case, budget, engineering resources, and infrastructure, and how the final model performs on different evaluation experiments.
There are several types of LLMs to consider.
Base LLMs
These are models that have usually been trained on very large datasets (like the whole internet) and are available for general-purpose usage. There are closed-source models like OpenAI’s ChatGPT, Anthropic’s Claude, and Google’s Gemini, and open-source models, like those offered publicly in Huggingface. These models often have multimodal capabilities and can serve multiple purposes, given that they are general enough.
Retrieval-augmented-generation (RAG) models
RAG can be seen as a solution lying halfway between using off-the-shelf models and custom fine-tuning. This is a technique where a model’s output can be enhanced by providing an extra “context,” usually by injecting it into the prompt after retrieving it based on some criterion and the user’s prompt. The context can be internal documents, a retrieved database entry, or any other extra information that might help the model provide correct output.
Custom fine-tuned models
Most off-the-shelf model providers (both open and closed source) also support fine-tuning the models on your custom data. This is useful, for example, when you are deploying an LLM that requires a certain level of specialization on a certain subject, and you have the resources to train a model on the data. You can also fine-tune models with prompts and desirable output pairs to ensure adherence to certain formats, phrasing, or tone.
Hybrid Approach
In the hybrid approach, your application uses multiple models (which can be both LLMs and non-LLM mixtures) to arrive at an answer to a given prompt. An example is when “cascading” LLMs, where smaller, cheaper models are run first for straightforward prompts and, if the output is not satisfactory by some metric or heuristic, a larger or more domain-specialized LLM is queried.
How to choose a deployment approach
When deciding on one of the approaches above, it is important to look at different factors. For each approach, the following table gives an idea of why you might prefer to use it.
Note that all of the methods above can be used with closed-source paid models as well as open-source models. With open source models, you don’t need to pay an upfront fee to use the model, since both the model architecture and weights are publicly available, but you would generally need more resources to “own” the whole deployment and fine-tuning stack, as there would be no specialized API support, etc.
{{banner-large-dark-2="/banners"}}
LLM application development and orchestration tools
The next step in optimizing your LLM application is to choose the right development and orchestration tools. These are tools that help you manage and deploy LLMs for more complex, customizable workflows beyond simple “prompt → output” behavior. This includes managing context and retrievals for RAG and orchestrating multiple models, if needed (for example, when using a multi-agent architecture or workflows in your LLM application).
There are several categories of development and orchestration tools:
- No code tools: These tools use a graphical interface to allow you to drag and drop the different components and LLMs in your system to define how they interact with each other and in what order. N8n and MakeAI are examples of these visual tools.
- Low-code tools: These are tools where a graphical (usually also flow-based) interface can be mixed with some code to modify or customize the behavior of the nodes. Dify and Langflow are good examples of this.
- High-code tools: These tools require more technical expertise because the flows and pipelines are code-heavy and highly customizable. This gives a lot of control with fewer restrictions and dependency on the tool’s support, resource management, and flow. Examples include LangGraph and DSPy.
- Proprietary in-house stacks: These are setups where internal teams fully implement and own the production and deployment code. This can be done using Python libraries and the provided model APIs from the different model providers, which are usually offered by the likes of OpenAI, Google, and Anthropic. Model formats like Pytorch, Onnx, and Tensorflow can also be directly used along with their respective inference APIs.
The right choice depends on many factors, like your engineering resources, machine learning expertise, and your priorities when it comes to usability trade-offs.
Data preparation and annotation tools
After deciding on a model and deployment/orchestration stack, you need to consider whether you will need to fine-tune your model on proprietary data. If so, you need to look at tools for LLM-specific annotation tasks that allow for easy LLMOps integration.
Key features of data annotation tools:
- Ranking model outputs for reinforcement learning from human feedback (RLHF)
- Support for specifying prompt-output pairs or other structured data for supervised fine-tuning (SFT)
- ML-assisted labeling, so you are less reliant on human labeling
- Cloud and API integration
- LLMOps integration
- Versioning and dataset management
Considerations and factors that go into choosing your data labelling tool:
- Supported data types: The tool should support the data formats you expect to fine-tune on, e.g., JSON, CSV, images, audio, or HTML data.
- Cloud, API, and LLMOps support: The tool should integrate and be scalable with your existing pipeline and cloud providers.
- User interface: Data annotation and labeling benefit from a clean interface that clearly shows the data pairs, labels, ranking, and any required information to evaluate and improve your model and data.
- Model-in-loop: It is often more efficient to rely on some annotation and ranking models to reduce the manual labour that goes into cleaning and optimizing your data for fine-tuning a model.
Examples of data annotation tools:
- SuperAnnotate: A well-rounded, multi-modal annotation tool with seamless ML-pipeline integration and built-in QA and analytics.
- Label Studio: An open-source and highly customizable annotation toolkit that supports many data types and can be extended with plugins and model-in-the-loop behavior.
- LabelBox: An enterprise-grade “AI data factory” that supports automated labeling using advanced techniques, including image segmentation, model-assisted labeling, and pre-labeling.
Prompt engineering and versioning tools
Prompt engineering is the practice of modifying or augmenting the user’s input prompt to produce a more accurate, relevant, or consistent model output. It is used in virtually all commercial LLM systems and is empirically proven to improve model performance.
Here are some examples of prompt engineering:
- Injecting a system prompt: This instructs the model on how to exactly answer a question or interact with the user at the beginning of an interaction. It can include explicit guidelines, constraints on output or tone, or general behavior instructions. System prompts usually persist throughout all of the session and can get quite detailed—Anthropic’s ClaudeSonnet’s system prompt is roughly 24,000 tokens long.
- Adding a “role”: This means instructing the LLM to respond as a certain persona, like a helpful assistant, a subject matter expert, or even a specific person.
- Adding “few-shot” examples, where you give the model a few ideal input-output example pairs. This helps the model give the output in the exact format you want for your application.
- Instructing the model to give a better thought-out response, e.g., telling it to think through the solution step by step, answer in bullet points, or give pros and cons.
Prompt versioning tools provide features for storing different prompts and prompt-engineering iterations, their evaluation results, and analytics to track things like accuracy, user satisfaction, or hallucinations with different prompts. This allows you to track the changes and associated benefits and regressions over time and fine-tune your prompts to get the best possible output from your model.
Here are some examples of these tools:
- Izlo has a user-friendly interface where you can log, compare, and evaluate different versions of your prompts. It offers strong testing and collaboration suites as well as an API that you can use directly in your application.
- PromptLayer provides version control and logs API calls and provides tools for A/B testing and associated evaluation and latency benchmarking. It also offers a no-code prompt editor for non-technical stakeholders.
LLM system evaluation and optimization tools
Consistent and continuous evaluation is arguably the most crucial aspect of deploying and optimizing LLM applications, since model performance varies over time and should be consistently tested for drifting, hallucinations, or failure cases.
It should be noted that the current paradigm of “vibe testing” or subjective (qualitative) inspection is not scalable or fit to optimize large LLM applications due to multiple factors:
- LLMs are non-deterministic, which means that different runs or the slightest variations on a prompt can yield different results. Subjective inspection can miss this kind of behavior.
- Model drift, where LLMs can behave in unexpected ways on out-of-distribution inputs (where the prompts come from a different distribution than the training or fine-tuning data). These need to be rigorously tested and improved upon with more user interaction.
- Slight improvements in some areas can lead to issues in others, so it is important to quantify and track these and correct for them or optimize the trade-offs.
- Gathering quantitative user data and feedback is critical to figuring out how to improve the LLM once it is deployed.
These tools can be integrated into many layers of your application, including initial testing and proof-of-concept demos to decide on a model, with different prompts and prompt-engineering approaches, after fine-tuning or RAG integration, and after the final deployment, once all of these design decisions are made.
LLM application deployment and scalability tools
A critical aspect of developing LLM applications is ensuring that you have a backend that balances reliability, performance, and cost as your user base grows.
One backend option for serving LLM applications is to use on-premises GPU instances, where you have your GPUs and servers (for example, Nvidia A100 machines) in a data center or server racks hosted in-house. This gives you complete control over networking, security, and hardware, but it also entails significant overhead with upfront and ongoing costs, maintenance, and engineering expertise.
Alternatively, cloud providers allow you to instantiate GPU instances on demand and scale as your user base grows, usually through dashboards and flexible pricing schemes based on your business needs. The platform providers handle all the required maintenance, OS/hardware requirements, and network setup, and they are starting to offer LLM-specific endpoints. Examples of these are Azure ML, AWS, Google Cloud, Together AI, and RunPod.
Here are some considerations for deciding on your deployment backend:
Scalability: The most important requirement is that the backend scales with the number of users. Cloud providers can seamlessly expand with more usage to handle more traffic (and contract when traffic spikes end, so you don’t overpay). On-premises hosting is usually limited in this area unless you have access to vast resources to procure and expand accordingly based on business needs.
Reliability: Ensure that the backend has built-in safeguards and quick turnaround times for failures, including redundancy, backup power, and security measures. These are usually automatic and handled in a timely manner by cloud providers. They can also be implemented on-premises, but are quite expensive and resource-intensive.
Cost: Depending on the expected user base and anticipated long-term expansion, on-premises hosting may be cheaper in the long run; however, cloud providers eliminate your upfront costs for hardware, data center maintenance, and engineering talent.
How Patronus AI Helps
Patronus AI offers best-in-class model evaluation tools that can be integrated with any layer in your code. It provides built-in evaluators to score and evaluate your model’s performance, as well as detailed metrics and visualizations that are easily understandable by non-technical stakeholders.
Here are some of the key features of Patronus AI:
- Built-in evaluators and LLM-as-a-Judge models: These can score RAG hallucinations, image relevance, context quality, and mode, which can be chosen from the predefined “remote” judges optimized for certain tasks..
- Custom evaluators: Patronus AI provides the ability to implement your custom logic and evaluators. These can be custom class-based evaluators (by extending StructuredEvaluator) for more complex logic or simpler function-based ones (by wrapping simple functions with FuncEvaluatorAdapter)
- Experiments: These allow you to configure custom evaluators and compare different model settings. You can measure pass/fail rates and review failure explanations with each update to the model, prompt version, RAG contexts, or dataset. This structured, data-driven approach ensures that you focus on the areas with the highest impact on performance.
- Monitoring and logs: Real-time analytics and detailed logs capture evaluation results, provide natural language explanations, and track failures in production, including hallucinations, RAG mismatches, and unsafe/harmful outputs.
- APIs and SDKs for multiple languages: There is full support for Python and TypeScript libraries and API calls, ensuring integration into your stack easily and reliably.
- Model Context Protocol (MCP) server: This feature provides a standardized interface for LLM system optimization, evaluation, and experimentation.
- Tracing: This feature gives you the ability to monitor and understand the behavior of your LLM applications through simple function decorators or context managers for specific blocks of code within functions.
- Percival: This state-of-the-art AI agent acts as a debugger for your LLM or agentic application. It is capable of detecting more than 20 failure modes in agentic traces and suggesting optimizations for LLM systems.
The following example demonstrates how to implement an LLM system with agentic capabilities and debug it using Percival.
Note: You can download the codes from this Google Colab notebook.
Run the script below to install required libraries:
!pip install -qqq smolagents[toolkit] smolagents[litellm]
!pip install -qqq openinference-instrumentation-smolagents
!pip install -qqq opentelemetry-instrumentation-threading
!pip install -qqq opentelemetry-instrumentation-asyncio
!pip install -qqq patronus==0.1.4rc1
!pip install wikipedia-api
The next step is to import the required libraries and initialize Patronus. Before running the script below, make sure you have the `patronus.yaml` file with the following credentials in the same directory where you run the code in this article:
project_name: "a-nice-project-name"
app: "a-nice-app-name"
api_key: "[Your key here]"
api_url: "https://api.patronus.ai"
otel_endpoint: "https://otel.patronus.ai:4317"
ui_url: "https://app.patronus.ai"
from smolagents import CodeAgent, Tool, LiteLLMModel, WebSearchTool,LiteLLMModel
import patronus
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
from opentelemetry.instrumentation.threading import ThreadingInstrumentor
from opentelemetry.instrumentation.asyncio import AsyncioInstrumentor
from datetime import datetime
import wikipediaapi
patronus.init(integrations=[SmolagentsInstrumentor(), ThreadingInstrumentor()])
import os
from google.colab import userdata
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
Now we can define a few tools for the LLM to use to answer your query: one to get a Wikipedia article summary and the other to return the URL. (Here is another example usage of the summary tool in an agent application that is also traceable with Percival.)
class WikipediaURLTool(Tool):
name = "wikipedia_url"
description = "Fetches a url of a Wikipedia page based on a given search query (only one word or group of words)."
inputs = {
"query": {"type": "string", "description": "The search term for the Wikipedia page (only one word or group of words)."}
}
output_type = "string"
def __init__(self, lang="en"):
super().__init__()
self.wiki = wikipediaapi.Wikipedia(
language=lang, user_agent="MinimalAgent/1.0")
def forward(self, query: str):
page = self.wiki.page(query)
if not page.exists():
return "No Wikipedia page found for your query."
return page.fullurl
class WikipediaSummaryTool(Tool):
name = "wikipedia_search"
description = "Fetches a summary of a Wikipedia page based on a given search query (only one word or group of words)."
inputs = {
"query": {"type": "string", "description": "The search term for the Wikipedia page (only one word or group of words)."}
}
output_type = "string"
def __init__(self, lang="en"):
super().__init__()
self.wiki = wikipediaapi.Wikipedia(
language=lang, user_agent="MinimalAgent/1.0")
def forward(self, query: str):
page = self.wiki.page(query)
if not page.exists():
return "No Wikipedia page found for your query."
return page.summary[:1000]
Now you can build the actual agent using your locally served LLM, as shown below. The Patronus decorator will do all the tracing for you.
@patronus.traced()
def main():
model = LiteLLMModel(model_id = "gpt-4o",
temperature=0.0,
api_key = OPENAI_API_KEY)
websearch = WebSearchTool()
wikisummary = WikipediaSummaryTool()
wikiURLtool = WikipediaURLTool()
agent = CodeAgent(name="agent",
tools=[websearch, wikiURLtool, wikisummary],
model=model,
add_base_tools=True)
agent.run("What are the criteria for winning the nobel prize winning criteria. Please also give me one or two relevant wikipedia article URLs.")
main()
The final output looks like this (excluding the full agent log):

Now you can easily head over to “Traces” in Patronus AI dashboard, where you will find your experiment and get a trace of the agent’s flow, as shown below.
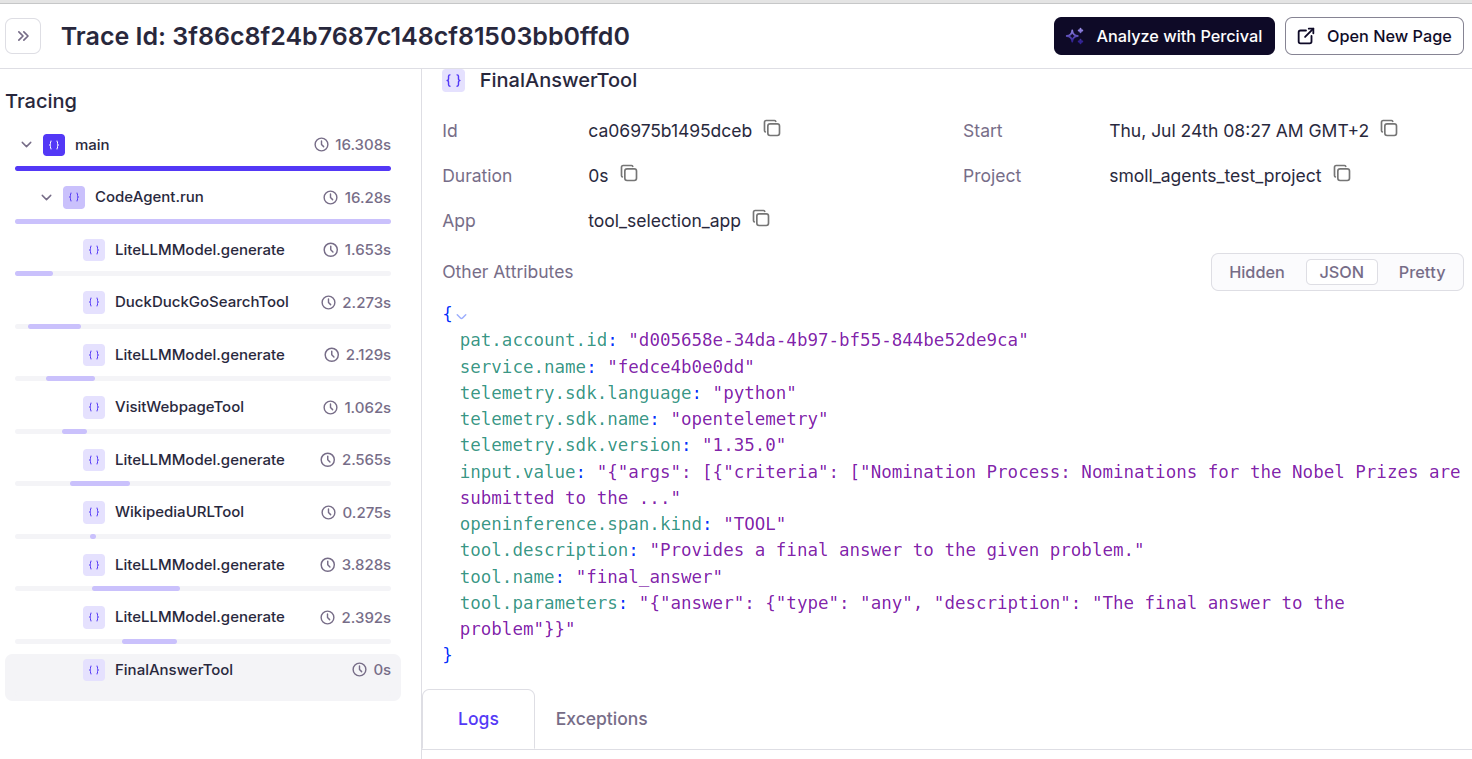
Click the “Analyze with Percival” button from the top right to get Percival’s insights. Note that it understands the task, assigns a score to different metrics of the final output, and gives clear suggestions to fix the problem. For example, in the following output, Percival suggests improving the prompt so that we receive the final answer as a string instead of displaying it in code block format.
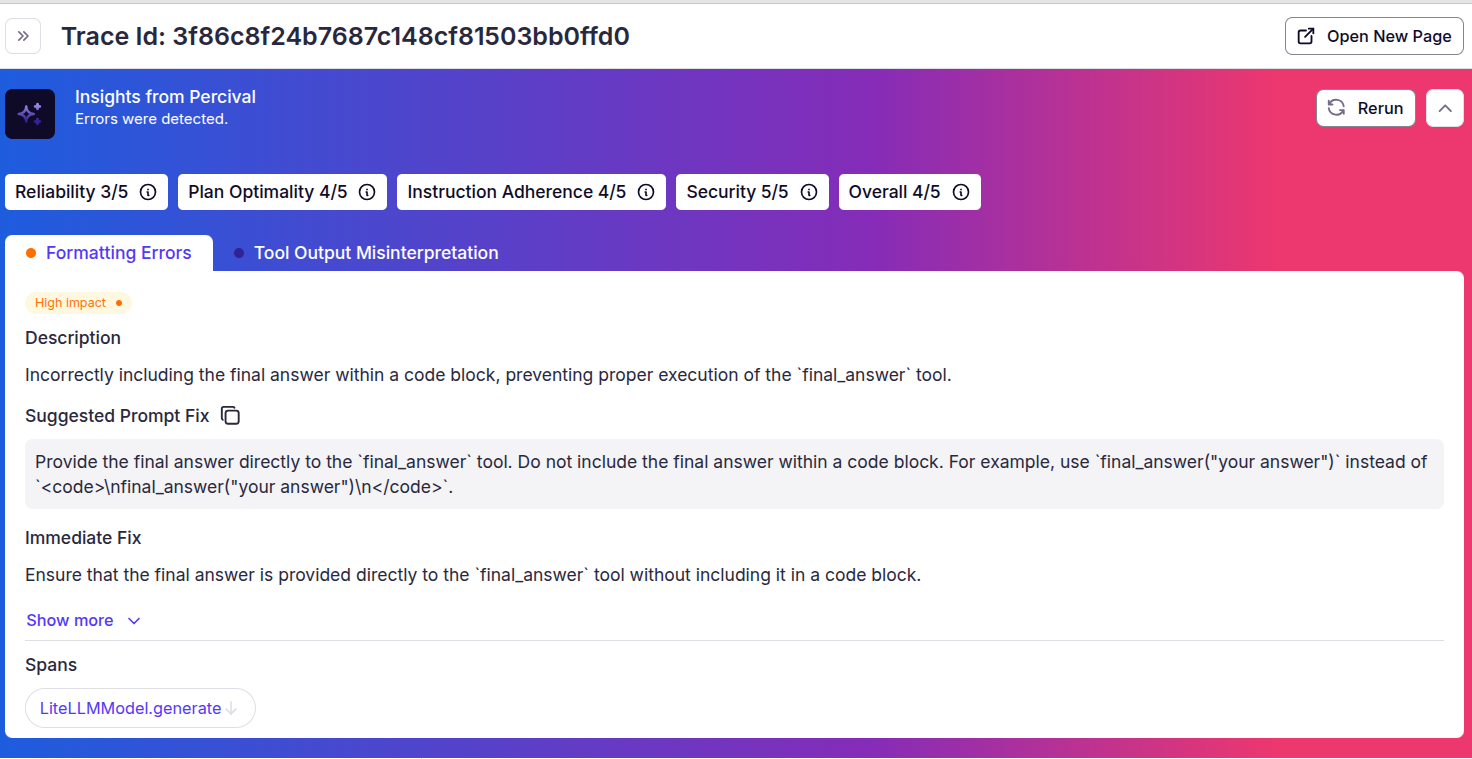
Now you can use Patronus AI and Percival to optimize and evaluate your LLM applications. For example, for the use case above, you can modify the prompt as suggested to explicitly instruct the LLM to provide specific criteria and prioritize general pages if exact matches are not found. Note that Patronus AI is platform agnostic and can evaluate AI models and agents developed on multiple platforms, which means it can easily be integrated into any deployment stack to optimize and evaluate your LLM application.
{{banner-dark-small-1="/banners"}}
Final thoughts
In this article, we covered many different concepts related to custom optimization tools and many types that you can use to develop and deploy your LLM application. These cover various layers, including initial model selection; no-code, low-code, and high-code orchestration and deployment tools; data preparation and annotation; prompt engineering and versioning tools; LLM evaluation and testing; and backend scalability tools.
No matter what the LLM-based application that you are developing does, you will need to consider all of these factors to deliver the expected user experience and achieve success. We have emphasized the importance of consistent, quantitative, and user-friendly evaluation and optimization to ensure the continued success of your product or application, as subjective or one-time evaluations are not suitable for large-scale LLM systems. Patronus AI provides all of these in one high-quality, reliable, and industry-leading product.Check out https://docs.patronus.ai for other use cases and more complex examples.