

Patronus Evaluators
Background
Patronus Evaluators are at the heart of our platform. They help users automatically evaluate their model on specific dimensions. We provide a suite of evaluators on the platform, but you can also create your custom evaluators. This overview covers our current offerings of evaluators and how to get started with them.
Patronus Evaluators
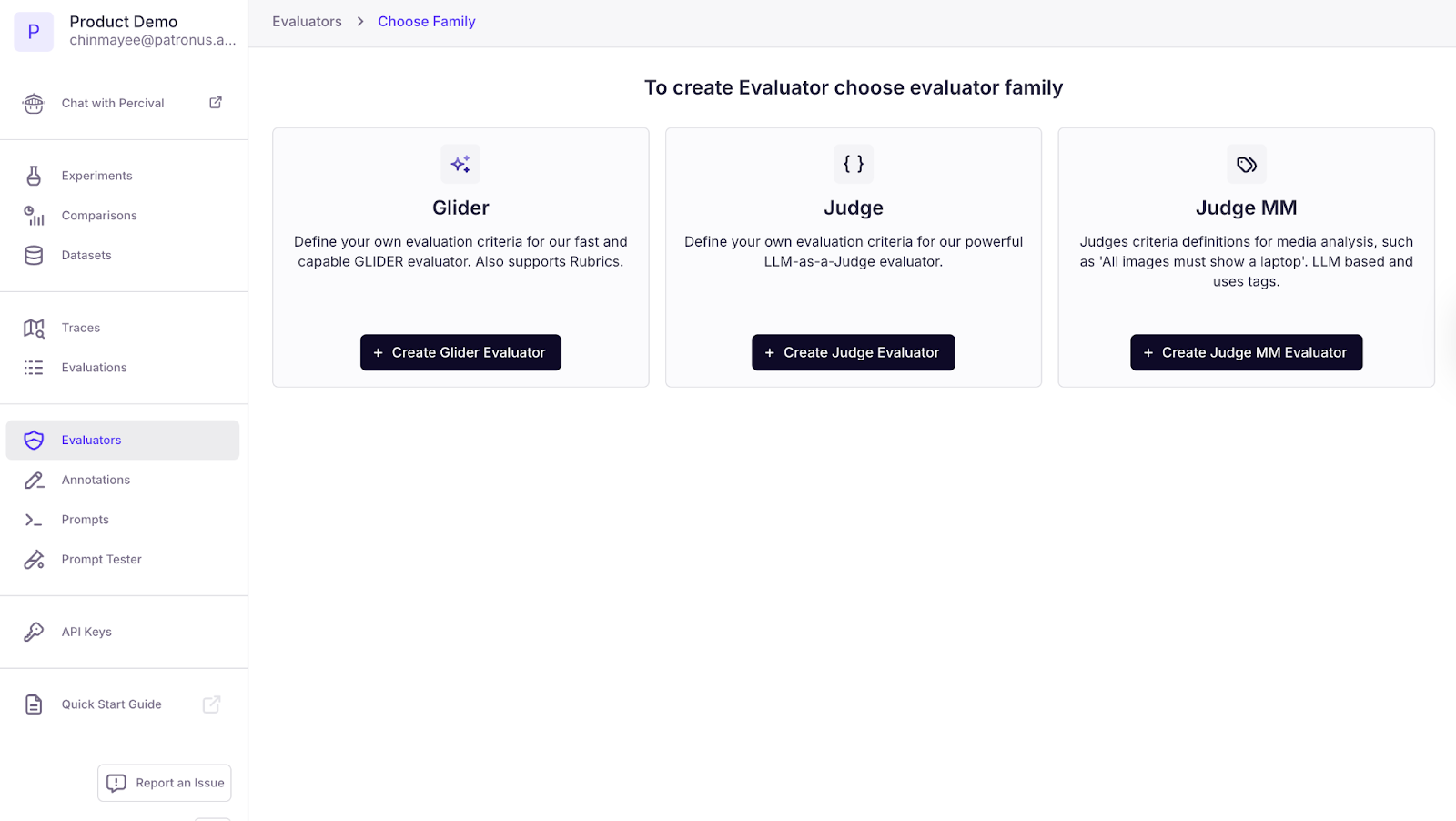
Our evaluators belong to specific families, such as:
- Glider - quick guardrails and checks, fast and accurate
- Judge - heavy reasoning, takes longer
- Judge MM - multimodal use cases, specifically audio and image
Glider evaluators are based on our in-house model and can support both binary and rubric-based evaluations. This is helpful for cases such as the development of a company chatbot that requires evaluation across multiple dimensions like relevance, tone, regulation, and safety.
Our Judge evaluators function are powerful and customizable LLMs-as-a-Judge that produce binary scores. Our Judge MM evaluators are based on Gemini and support media analysis use cases.
We have evaluators specialized to test for concepts like answer relevance or hallucination, and they are based on various scorers or classifiers. Each evaluates a single sample and runs independently of the others. These evaluators run on Patronus’ infrastructure and automatically scale to your needs, and you can also upload evaluations run locally to Patronus.
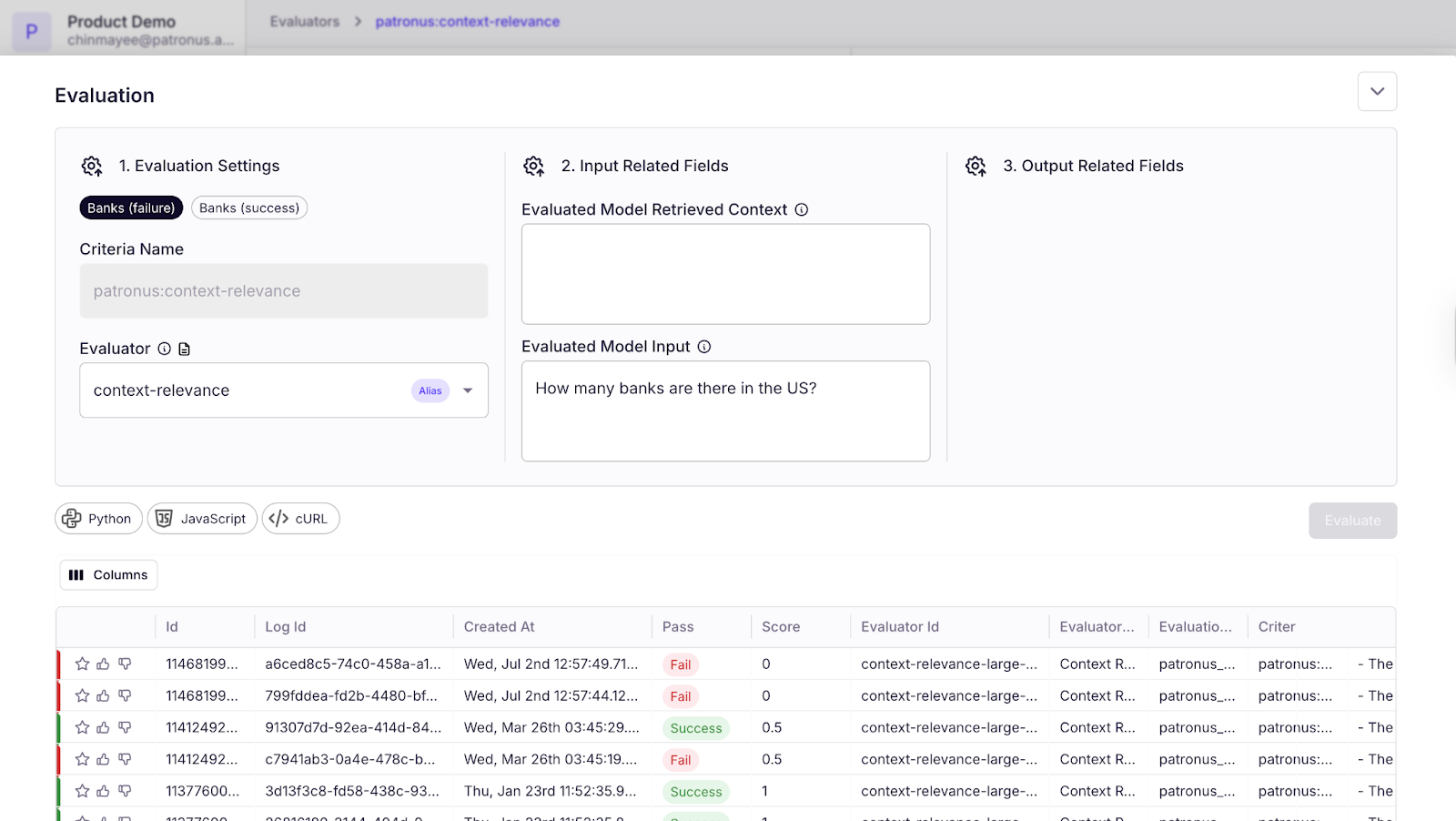
Evaluators consist of four components: input, output, retrieved context, and gold answer.
- Input: the prompt for the model
- Output: the response from the model
- Retrieved Context: any context provided to the model to ground the answer
- Gold Answer (Optional): the ground truth answer that the model should return
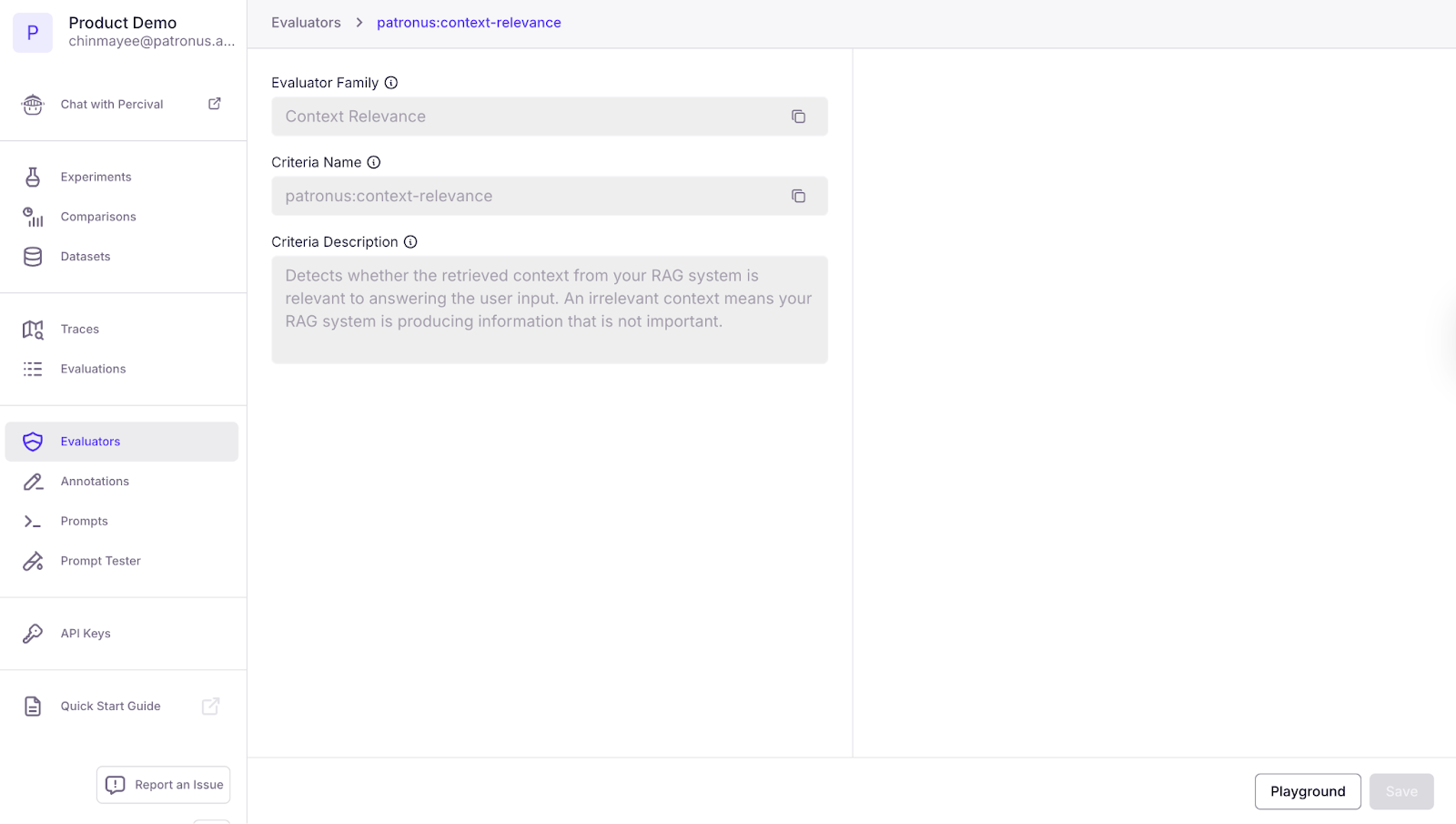
Off-the-Shelf Judge Evaluators: Retrieval and General Dimensions
These evaluators are developed in-house by our research team and are continuously assessed and improved according to performance on real-world benchmarks.
Retrieval
Our evaluators can check for hallucinations, context relevance and sufficiency, and answer relevance. These tests are used to ensure the model is staying on topic, grounded in provided information, or is retrieving the right information for the task.
- Hallucinations - evaluators focus on hallucination testing to ensure that a model is only referencing context provided. They flag outputs that include fabrications and misrepresenting facts.
- Context Relevance - this category focuses on ensuring that the system is producing important and relevant information to the topic.
- Context Sufficiency - this type of evaluator ensures that the context provided is enough to obtain the gold answer.
- Answer Relevance - the evaluator focuses on ensuring that the model is staying on topic and producing responses related to the query.
The retrieval-based evaluators are good for companies testing early solutions of their AI applications, whether they are company-specific models, chatbots, or agents. These evaluators form the foundation of your evaluations and lead to more complex, nuanced tests denoted below.
General Dimensions
We also offer evaluators that cover more general areas for enterprise concerns, such as enterprise PII, toxicity, and traditional NLP metrics, among others. These check for areas that enterprises would evaluate their other tech products for, ensuring the same standards for AI applications.
- Enterprise PII - this evaluator can help you protect information like usernames, email addresses, social security numbers, IP addresses, location, and other business-sensitive data.
- Toxicity - this can flag different types of toxic content, such as threats, insults, and profanity.
- NLP Metrics - this evaluator can assess your model on things like bleu score or rouge score, among other defined metrics
Our evaluators, focusing on general enterprise dimensions, are good for teams who are past the checks for quality and relevance and are now approaching territory that is harder to robustly test with their internal capabilities alone.
Custom Evaluators
Custom evaluators can be designed by users. You can customize our Judge and Glider evaluators based on your own pass criteria and score rubrics. These can be tailored for your specific use case, whether it's assessing behavior based on your company policies to adhering to your industry’s regulatory standards, to maintaining a particular tone among many others.
- Company - some offerings can be designed based on regulatory requirements, company policies, or brand alignment guidelines. These ensure that an AI application is operating appropriately along hard constraints.
- Style - evaluators can also be configured to test for a particular tone of voice, preference on concision or verbosity, or usage of certain language.
- LLM-specific Guardrails - lastly, we have seen companies configure their evaluators for dimensions more associated with AI concerns like bias and authenticity.
For companies developing chatbots or company-specific AI tools, custom evaluators offer a good balance between leveraging SoTA techniques and incorporating customizations to fit your needs.
Evaluators in Use
Several companies have seen big early wins with the usage of Patronus evaluators across use cases like relevance, hallucination, and multimodal evaluations.

Gamma has saved 1,000+ manual evaluation hours by using Patronus Judges to assess concepts like factual completeness, content length coverage, structural completeness, and instruction following. Read more about it here.

Algomo doubled its hallucination detection solution from 0.375 to 0.69 with the use of our Lynx model, which helps with hallucination evaluations. Read more about it here.

Etsy used multimodal judges to gauge the effectiveness of different image captioning models. Patronus captures and renders the input image, confidence score, and reasoning, which is used with our Experiments feature, helped the team improve image captioning and hallucination scores. Read more about it here.
Conclusion
We understand that there is no one-size-fits-all solution for evaluation. That’s why Patronus Evaluators are meant to help you lay your foundation and build more customized solutions tailored to your industry, company, or use case needs.
Read more on our Evaluator Documentation here. If you have any questions, our team is happy to help you set up your evaluation. Contact us at contact@patronus.ai!

