


Introducing MEMTRACK: A Benchmark for Agent Memory
MEMTRACK: Evaluating Long-Term Memory and State Tracking in Multi-Platform Dynamic Agent Environments
Background
At Patronus AI, our work in agent evaluation probed us to think further about agent capabilities. What are agents missing that in real-world settings help humans achieve complex objectives? Memory came to mind.
Memory allows us to acquire, store, and apply information across a variety of settings and durations. We can remember the context a coworker gave us in a meeting while completing a new task a few days later. We can remember that a store is closed on a specific day when making plans for the following week.
Memory helps us hold context, and context allows us to perform tasks optimally.
MEMTRACK Dataset
With MEMTRACK, we want to begin addressing long-term, cross-platform memory questions for agentic systems. We simulate a software development environment in which the agent has access to Linear, Slack, and Git servers and with tools is given access to an organization’s event timeline, which we populate with three distinct event history creation methods. These events provide context for what the agent should do. The agent is then responsible for working off of this context, using the right tools, and completing a series of related tasks.
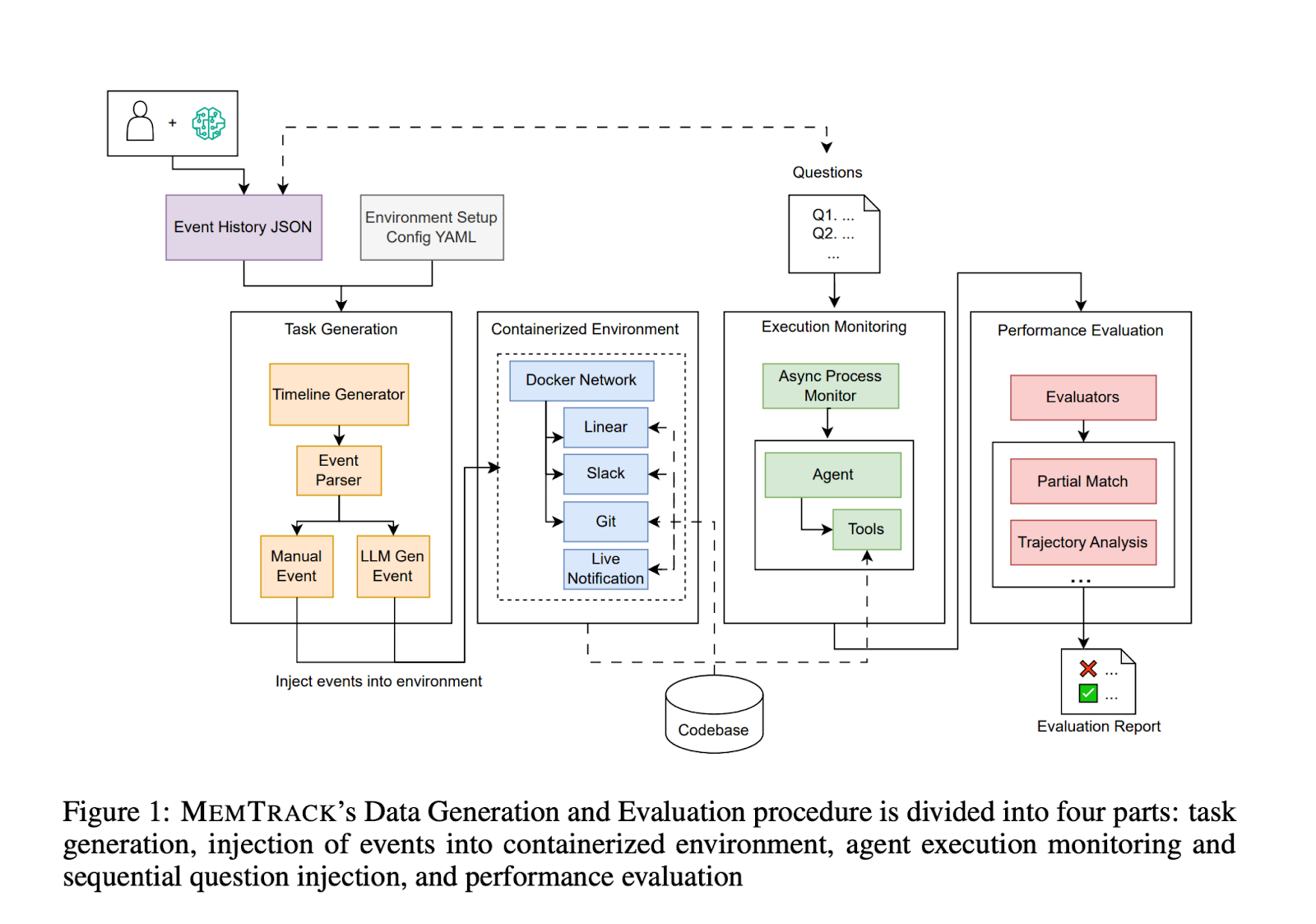
We started with the development of a rich event timeline.
Bottom-Up Approach - Open-Source Repositories
The first way we populated the timeline is with a bottom-up approach. We created data points and realistic scenarios utilizing closed issues on popular, open-source repositories. To this, we added more contextualized data and real-world distractions to simulate typical SWE work settings. We combine this with the actual solution implemented in the final PRs of those repositories.
Top-Down Approach - In-house Experts
The second way is by building on the experiences of in-house experts who previously worked in product and engineering organizations, collaborating with multiple teams. Through this, we developed real-world workflows of how problems are scoped, defined, communicated, and solved by teams.
Hybrid Approach - Blending Both
The last approach was a mixture of the two above. Given high-level ideation from experts, data annotators prompt LLMs with task context, motivation, end goals, and the codebase. Annotators then iteratively work with the LLM to increase the complexity of the event history and then attempt to manually solve the task to ensure completeness of the procedure.
Experiment
We set up our experiment with the following:
- LLM + NoMem: agent is operating without within-agent memory components included
- LLM + MEM0: agent has a within-agent MEM0-based memory component
- LLM + ZEP: agent has a within-agent ZEP-based memory component
Evaluation & Results
We evaluated success based on three dimensions: correctness, efficiency, and tool call redundancy.
- Our results show that GPT-5 and Gemini-2.5-Pro invoke tool calls successfully.
- The memory components don’t cause a significant improvement in performance. Likely because when provided with memory tools, LLMs fail to call them effectively.
- There is a performance decay with follow-ups, a finding that persists across the methods tested, indicating that agents struggle to manage multi-turn context.
- We see given GPT-5’s ~60% performance on MEMTRACK, there is room for improvement on large context reasoning and understanding of follow-up questions.
Conclusion
We conclude that given agents are successful in invoking regular tool calls with appropriate training, agents would improve in their large context reasoning and understanding of follow-up questions with practice using memory tools. As we work on more complex forms of agent evaluation, building with memory in mind will allow agents to achieve complex objectives across domains using a variety of platforms.
We’re excited to build agent memory advances with the research community! Reach out to us if you want to collaborate or learn more.
arXiv Paper: https://arxiv.org/pdf/2510.01353

