

AI Agent Platforms: Tutorial & Comparison
Calling an LLM from an API is easy. However, building an agent that can remember, reason, and take action independently is a whole different level of complexity.
AI agents are no longer just a research curiosity. They’re starting to power real systems. With numerous platforms available, determining which one suits your needs or whether you even need one can be challenging.
This article breaks down the main types of AI agent platforms, the tradeoffs they involve, and the engineering decisions you’ll face along the way. Whether you're an engineer exploring orchestration frameworks or a data scientist looking to integrate evaluation into your pipeline, this guide is here to help you navigate with confidence.
Summary of key AI agent platform concepts
What are AI agent platforms?
AI agent platforms manage workflows that go beyond a single LLM prompt. They help coordinate tasks, maintain context, and connect with external tools or APIs, allowing language models to operate more like systems than standalone responders.
For example, say you need an LLM to draft a brief, pull internal documents, fact-check through an API, and format a report. Agent platforms enable the creation of that sequence flow without manually stitching every step together.
Key features
- Managing memory and context
- Routing and tool execution
- Delegating tasks across roles
- API integration
- Debugging and assessment help
- Observability, optimization, and evaluation.
Your team's demands and system complexity determine which platform to use—visual or code-driven.
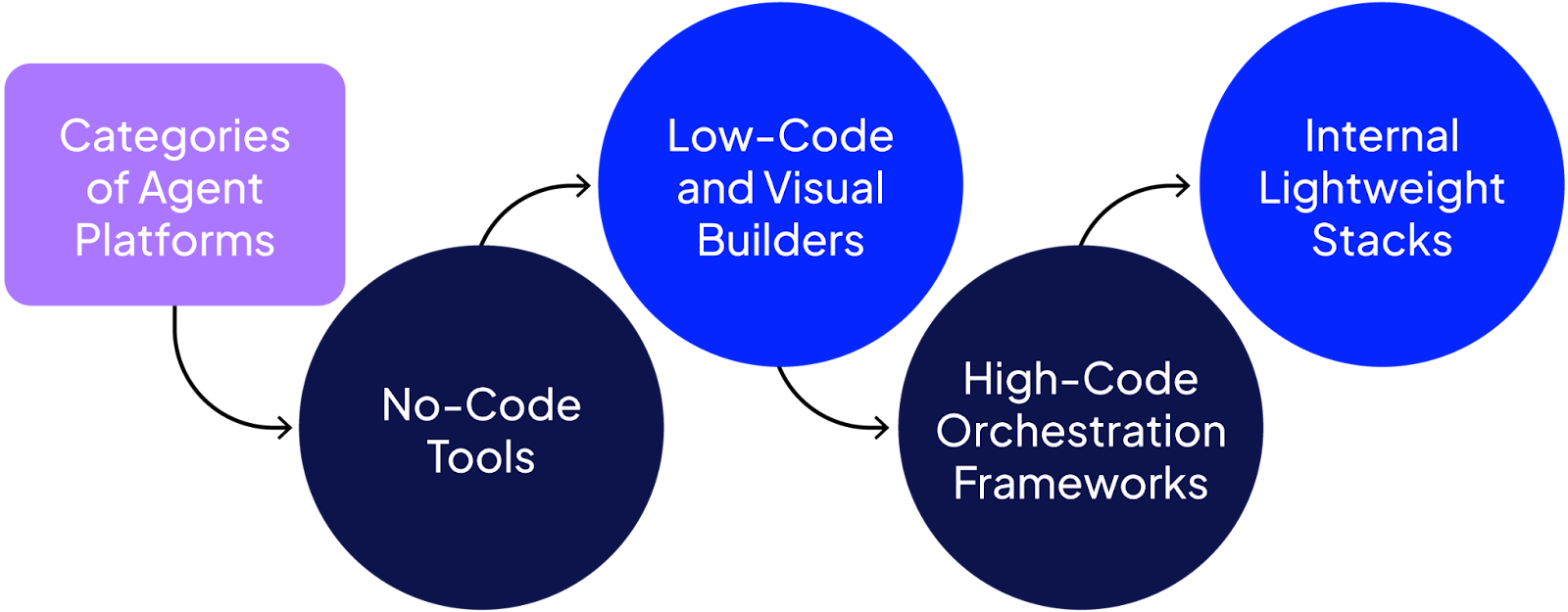
AI agent platforms categories
AI agent platforms can be grouped into the following categories
No-code tools
Tools like n8n and Make.com let you compose flows visually using blocks or drag-and-drop elements. These platforms shine in speed of deployment and ease of integration. They are ideal for rapid application deployment and integration-heavy tasks.
Low-code and visual builders
LangFlow is a good example here: a visual layer built on top of LangChain that helps you link prompts, chains, and agents without requiring extensive code modifications. These are excellent for prototyping and internal demos.
High-code orchestration frameworks
Platforms like LangGraph, CrewAI, DSPy, and AutoGen provide engineers with full control over memory, execution paths, and tool usage. These work best for teams with a strong backend infrastructure and engineering capabilities.
Internal stacks
Some teams construct agent flows internally using LiteLLM, OpenAI SDKs, and event loops. This strategy provides maximal control, no platform lock-in, and enhanced observability but requires building basic functionality in-house.
{{banner-dark-small-1="/banners"}}
Comparing popular AI agent platforms
The table below provides a side-by-side comparison of popular agent frameworks, so you can quickly assess their differences across key areas, including orchestration, integration, hosting, and learning curve.
LangGraph (Python Agent Workflows)
LangGraph is a Python library for building robust, long-running AI agents using a graph-like workflow. It focuses on stateful execution and integrates with LangChain tools to coordinate complex tasks. Despite its advanced capabilities, you can get started with a simple agent and a few lines of code.
For example, the snippet below creates a basic LangGraph agent with a single tool and runs it on a user query. The agent uses a built-in ReAct template and an OpenAI model.
# pip install langgraph
from langgraph.prebuilt import create_react_agent
def get_weather(city: str) -> str:
return f"It's always sunny in {city}!"
agent = create_react_agent(
model="openai:gpt-3.5-turbo",
tools=[get_weather],
prompt="You are a helpful assistant."
)
# Invoke the agent on a question
response = agent.invoke({"messages": [
{"role": "user", "content": "What's the weather in Paris?"}
]})
print(response)
(This uses LangGraph’s prebuilt ReAct agent to answer a weather question with a dummy get_weather tool.)
CrewAI (Multi-Agent “Crew” Framework)
CrewAI is a Python framework for orchestrating multiple AI agents (“crew members”) that collaborate on tasks. It offers high-level simplicity (YAML or code configs) and low-level control for autonomous agents. Each agent has a role and goal, and they can work in sequence or in parallel (via Crew objects) to solve complex problems together.
Below, we define two simple agents and tasks in code, then combine them into a crew and run it. One agent acts as an analyst and the other as a researcher, working sequentially on their tasks.
# pip install crewai
from crewai import Agent, Crew, Task, Process
# Define two agents with distinct roles
analyst = Agent(role="Analyst", goal="Analyze provided data")
researcher = Agent(role="Researcher", goal="Gather supporting data")
# Assign a simple task to each agent
analysis_task = Task(description="Analyze the data", agent=analyst)
research_task = Task(description="Find supporting data", agent=researcher)
# Create a crew with both agents and tasks, and run it sequentially
crew = Crew(agents=[analyst, researcher], tasks=[analysis_task, research_task], process=Process.sequential)
crew.kickoff(inputs={"data": "Example dataset"})
CrewAI allows defining agents in code as shown, then executing them as a team. In practice, you might configure agents and tasks in YAML, but the above demonstrates the basic Python API.
smolagents (Hugging Face Lightweight Agents)
smolagents is a lightweight Python library by Hugging Face that simplifies the creation of AI agents, making them accessible to developers. Agents in smolagents use large language models to generate Python code that invokes tools (like web search or image generation). This approach keeps the framework simple while allowing powerful actions.
In this snippet, we utilize smolagents to create a code-writing agent that integrates with a web search tool. The agent is then asked a question that requires it to search for information.
# pip install smolagents
from smolagents import CodeAgent, DuckDuckGoSearchTool, HfApiModel
agent = CodeAgent(tools=[DuckDuckGoSearchTool()], model=HfApiModel())
result = agent.run("How many seconds would it take for a leopard at full speed to run across the Golden Gate Bridge?")
print(result)
Here, the CodeAgent will use the DuckDuckGo search tool to find information and calculate an answer, all by writing and executing code under the hood.
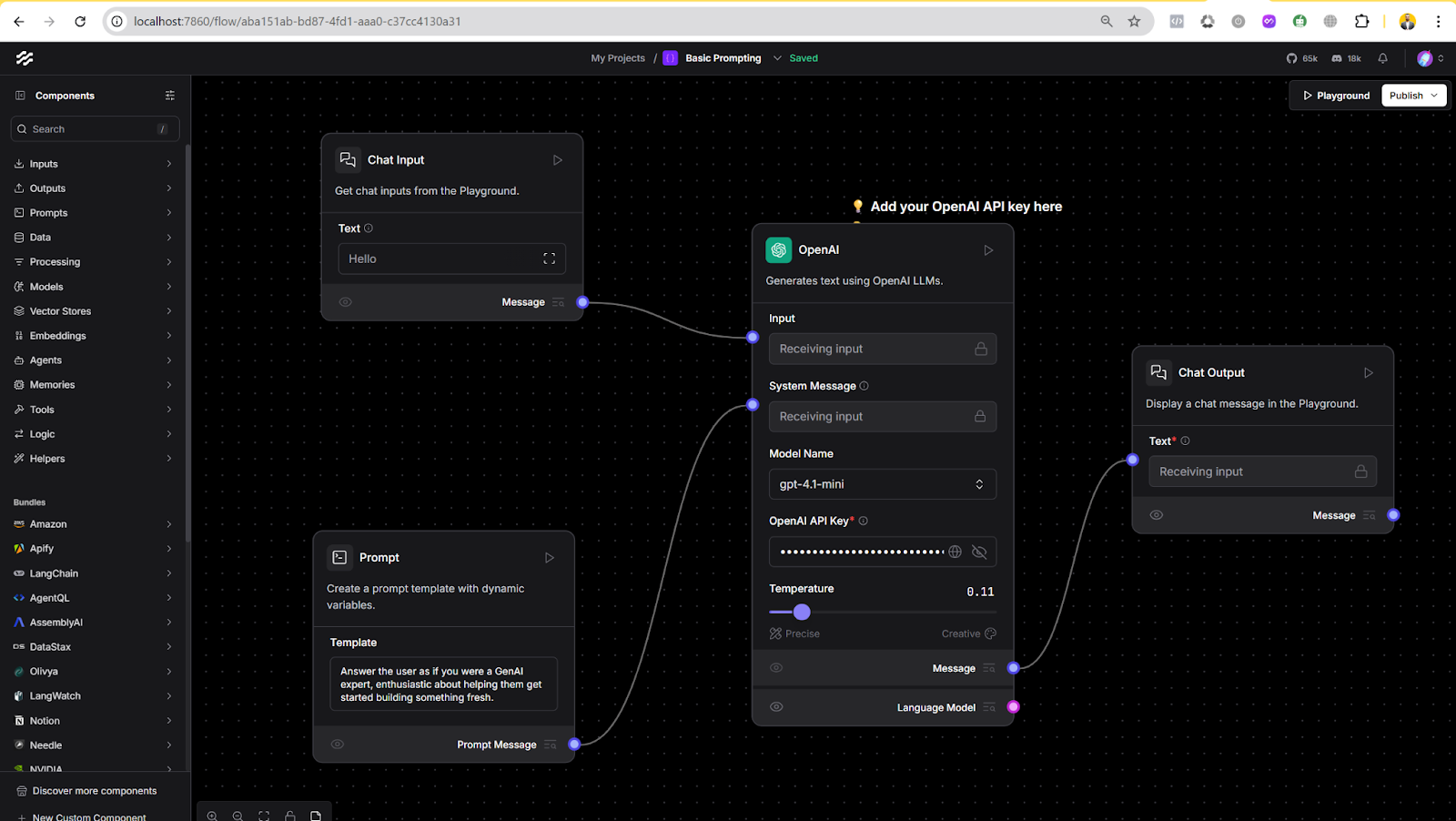
LangFlow (Visual Flow Builder for LLMs)
LangFlow is an intuitive no-code visual interface for building AI workflows with LangChain components. It provides a drag-and-drop canvas to connect LLMs, prompts, tools, and data sources into a flow. This is ideal for users who want to prototype or deploy AI agents without needing to write code. Each flow can be run in the browser and even exported as an API endpoint.
To get started with LangFlow, install the package and launch its web UI. With Docker installed and running on your system, run this command:
docker run -p 7860:7860 langflowai/langflow:latest
Langflow is now accessible at http://localhost:7860/.
Once running, you can visually create a new flow (for example, a basic chatbot with a prompt node and an LLM node) and then execute it in the LangFlow interface. LangFlow converts each created agent or workflow into an API that you can integrate into other applications.
n8n (Open source workflow automation)
n8n is an open-source, node-based workflow automation tool for connecting various apps and services. While not AI-specific, it can integrate with AI APIs (like OpenAI) through its nodes. You build workflows in n8n’s editor by chaining nodes (triggers, actions, transformations) – no coding required. This flexibility allows orchestrating AI tasks alongside other automation (e.g., run an AI text generation whenever a new form submission arrives).
n8n can be self-hosted. For example, using Node.js and npm:
# Install n8n globally
npm install -g n8n
# Start the n8n editor (opens at http://localhost:5678)
n8n start
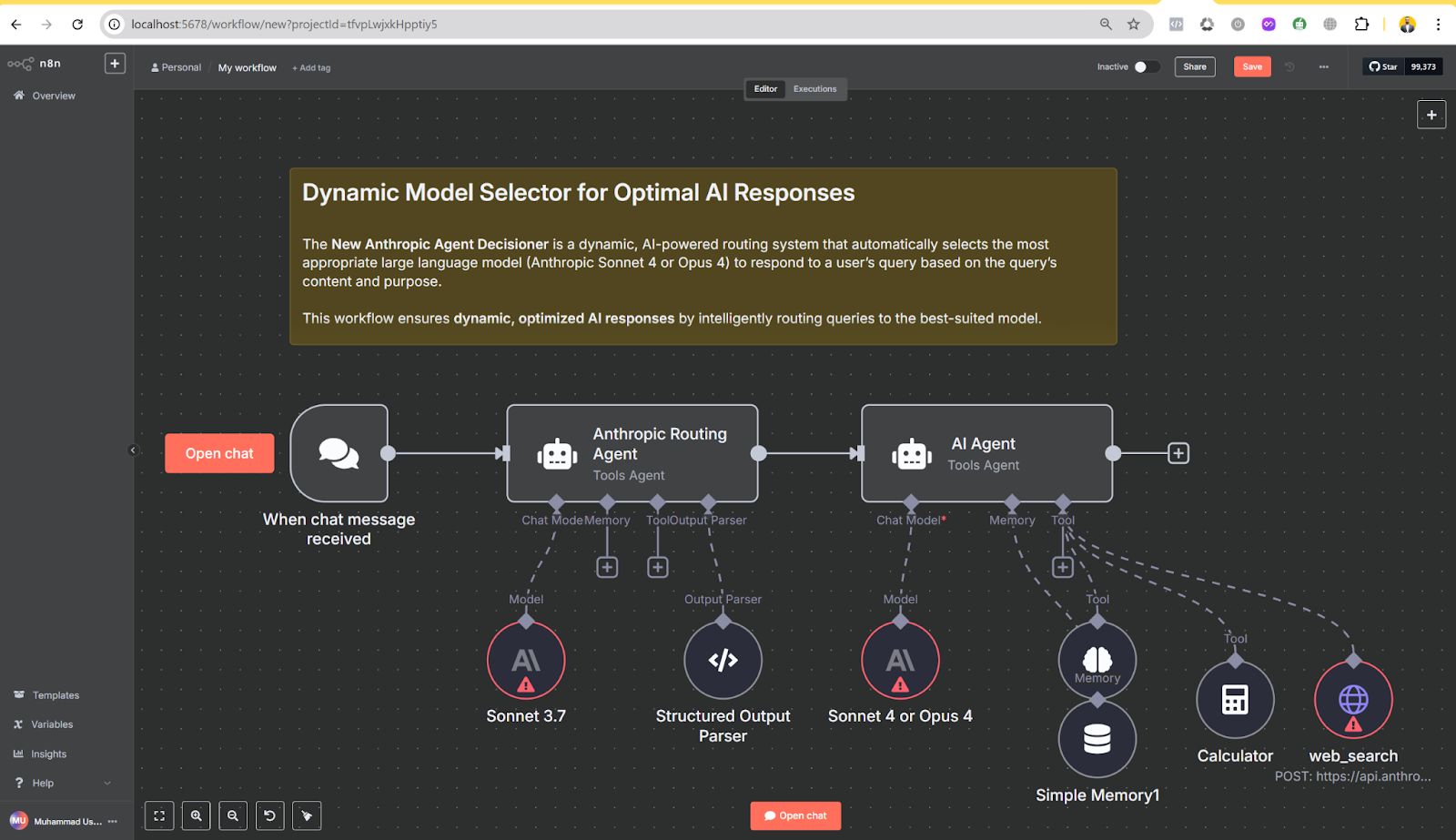
After running the above, you can open n8n’s browser-based editor to design a workflow. For instance, you might add a Webhook trigger node (to receive a request), then an OpenAI node to generate a response, and finally a response node to reply – creating a simple AI-powered automation. (n8n’s cloud version is also available if you prefer not to self-host.)
Selecting the right AI agent platform
A well-suited platform simplifies integration with your existing tools, data, and workflows, while also enhancing scalability, efficiency, and performance.
Integration capabilities
Let your product goals lead the way: if the agent must pull data from your CRM, trigger DevOps pipelines, or sync with other in-house tools, invest in a framework that offers robust connectors and extensible APIs. If those integrations aren’t critical, favour a lighter platform that maximises speed and simplicity instead of spending time wiring up features you won’t use.
API & tool connectivity
Many AI agent systems have connectors or plugins for third-party tools, including Slack and CRM systems, allowing the agent to perform real tasks within your environment. A good integration layer for web services, databases, etc. facilitates the agent's inclusion into processes more readily.
Database and knowledge access
One should verify database connector support and retrieval capabilities. The system should enable agents to directly access knowledge bases or databases. Some systems provide vector database connections or retrieval-augmented generation (RAG) support, which is especially important for agents that need to pull relevant context from your material stores during generation.
Cloud-native integration
Can the system run on your cloud and work with existing cloud services? It should support cloud-native credentials management, serverless execution, and container-based deployment, such as those offered by AWS, Azure, or Google Cloud.. Ensure it functions on your cloud or on-premises without significant modifications. Cloud-friendly systems for microservice architectures often include scalability and integration capabilities.
Customization & flexibility
Some teams require the flexibility to customize how agents operate internally—whether that involves memory handling, tool logic, or prompt control.
Memory management
Evaluate how the platform handles both short-term context (like recent conversation history) and long-term memory (via vector stores or embedded knowledge). Depending on your use case, you may want support for memory routing, where an agent intelligently selects examples of past interactions or stored knowledge to include in its current prompt. For example, a tutoring assistant explaining new concepts based on a student’s learning history would benefit from memory, while a bot answering one-off shipping status queries may not require it. Proper memory management ensures that responses stay accurate and context-aware as the task evolves.
Dynamic tool usage
The platform should accept customization and extensions. Check if agents can call custom tools or APIs and enable or disable them dynamically. A modular framework with swappable tools, chains, etc. allows custom logic and behavior. If your agent needs to perform multiple actions like checking weather, querying a database, and formatting a report, it’s important to avoid a fixed toolset. That said, fixed toolsets are valuable when you want predictable behavior. For instance, if your agent must always call a specific financial API to verify transactions, a restricted set of tools makes it easier to spot issues when something breaks.
Prompt management support
Implement a robust prompt template and agent instruction management rather than relying on a single, generic prompt. Craft system messages, role directives, and formatting rules to fit each use case, user segment, or workflow stage.
Modern orchestration frameworks offer utilities for defining, testing, and optimizing prompts, allowing you to precisely shape the agent’s persona, tone, and behavioral guardrails. Fine-grained prompt control yields responses that consistently reflect your brand's voice and task objectives. You also don’t have to manually chase model‑agnostic phrasing—many platforms (e.g., Langfuse) abstract differences between underlying models and handle interpolation or formatting automatically. Adding dedicated prompt management with version control (treating prompts like code) improves traceability, enables safe iterative experimentation (A/B tests, rollback), and ultimately makes the application more maintainable and scalable.
Technical requirements
Here are a few technical aspects worth reviewing before committing to a specific platform. Each choice reflects trade-offs, so it's worth asking what your team actually needs before optimizing for complexity.
On-premises vs. cloud
Do you need full control or sensitive data handling? Hosting on your own servers may be necessary. While it offers more flexibility, it also means taking care of uptime, scaling, updates, and hardware.
In contrast, managed cloud services are easier to set up and maintain but come with some trade-offs in control. Your decision should reflect your compliance needs, internal capacity, and deployment preferences.
Containerization & portability
If you are already using Docker or Kubernetes, ensure the platform integrates smoothly with these environments. Containerization packages your application and its dependencies into isolated units, making them easier to deploy consistently across machines. This becomes especially helpful when you need to scale workloads or move between environments.
Hardware and LLM support
Some platforms require local model execution, which means you’ll need GPU access. Others rely on external APIs, such as OpenAI or Anthropic. Be sure to assess your available compute resources, whether on-premise or in the cloud, so you can choose a setup that aligns with your infrastructure.
Ecosystem & compatibility
Stick with tools that fit smoothly into what you already use. That means checking support for your databases, ML tools, deployment processes, and so on. Also, ensure there is an SDK in the language you’re working with.
Evaluation & debugging
Consider the following for ongoing system maintenance.
Logging, tracing & LLM observability
Logging and tracing are essential for any agent system. They allow teams to see exactly what the agent did, when it did it, and why. Capturing every input, output, and decision point is our most important recommendation to customers. Without this visibility, diagnosing errors or validating results becomes a matter of guesswork.
LLM observability adds another layer by showing how the model thinks—how it forms prompts, uses context, and generates responses. This feature is critical to understand how results are obtained and fix errors
Tools like Patronus AI help teams trace agent behavior and model reasoning in one place, making it easier to debug, improve, and trust your system.
Debugging tools & hooks
Good platforms allow you to inspect the agent's behavior. Some let you run steps live or observe how the agent processes a task. The ability to halt, execute, and examine a test result saves a lot of time during development. Platforms like LangGraph and CrewAI offer this level of step-by-step execution and inspection, making them particularly useful during testing and debugging. Also, frameworks like n8n also let you run the agent in steps, so you know what is happening under the hood.
Error handling & guardrails
Failures can occur, including unexpected LLM responses, tool output issues, or API call errors. When used for critical use cases, the agentic framework should support safety fallbacks, error handling, and retry management. It is also beneficial if the system includes validation layers that prevent unnecessary or irrelevant output.
Other criteria
Licensing model
Review the license terms early. Open-source platforms often offer greater transparency and control, but some may impose restrictions, particularly regarding commercial use. For example, on Hugging Face, any licence containing “-nc-” (e.g., cc-by-nc-4.0) or labelled “research-only” (such as fair-noncommercial-research-license, intel-research, or apple-amlr) forbids commercial use—you may only experiment or publish non-profit research with those models or datasets.
For revenue-generating projects, you’ll need a permissive licence (Apache-2.0, MIT, BSD, OpenRAIL-M/++) or explicit written permission from the right-holder. Commercial tools are typically easier to set up and use, but they usually come with licensing fees. The tradeoff is often between cost and control rather than functionality or flexibility.
Language & team fit
Just ask—what’s the team comfortable with? If everyone codes in a particular technology stack and you hand them another technology stack to work with, it will be a pain. Also, does the team want a visual tool or something they can script? Consider who will be responsible for maintaining the system on a day-to-day basis. For project managers or less technical staff, a drag-and-drop interface might be a good option, whereas experienced systems engineers may prefer a fully code-driven approach with greater flexibility.
Pricing & cost structure
Cost models can vary significantly. Platforms charge based on the number of users, usage volume, or token consumption. Although many open-source options appear free at first, they often require additional engineering resources, infrastructure, or long-term maintenance. Before fully adopting a solution, consider testing it in a small-scale project to understand actual usage patterns and internal resource demands.
Security & compliance
If you’re handling private data, vet encryption, RBAC, and logging — and insist on independent audits such as SOC 2 Type II; platforms like Hugging Face Enterprise Hub and Databricks already publish current SOC 2 reports
Even so, tightly regulated workloads may still require on-prem hosting, while SaaS remains the fastest route if you trust the provider’s audited controls and data-handling practices.
Ecosystem maturity
Docs and GitHub issues are necessary for developer support. A platform with an active Discord or forum is a significant advantage. If nobody’s using it yet, expect to hit some unexpected behavior.
Custom build vs. using a platform
If your use case is light—just an API call or two—customising might be easier. A small script and a vector DB often do the trick. Frameworks can hide steps or abstract away logic, making it more challenging to trace bugs. If you need to know exactly what’s going on, keeping it custom might be easier.
If wrong answers are a deal-breaker, some tools provide built-in checks. Still, implementing your own flow lets you plug in your own guardrails or data lookups. That’s big if you care about accuracy.
However, if you want your agent to interact across multiple tools, decision points, or long workflows, it is recommended to use AI agent platforms. They handle memory, tool routing, and other implementation details. Customizing can scale out quickly, making the system challenging to maintain.
Comparison: Custom Build vs. AI Agent Platforms
Evaluating AI agent platforms with Patronus AI
Patronus AI is a platform-agnostic evaluation tool that helps assess the reliability of agent pipelines built with frameworks such as LangChain/LangGraph, CrewAI, and custom-built in-house applications. It excels at measuring accuracy and providing rich feedback on agent behavior.
Key features include:
- End-to-end agentic debugging with Percival: Percival, a model developed by Patronus, is an AI debugger that identifies issues in various components of your Agentic AI application and suggests improvements.
- Hallucination detection: Patronus utilises models like Lynx to identify unsupported or fabricated facts in agent outputs, especially crucial in retrieval-augmented setups.
- Accuracy & relevance: Evaluators such as Exact Match and Answer Relevance automatically validate if agent responses are both correct and on-topic.
- Integration with major AI platforms: Patronus provides integrations for nearly all major AI platforms, including LangChain, HuggingFace, CrewAI, and OpenAI.
- Real-time & batch evaluation: With low-latency judge models like GLIDER, Patronus enables continuous QA—automating what would be hours of manual review.
- Interpretability: Patronus provides justifications for every flag or failure, enhancing transparency and debugging.
Evaluating a LangGraph RAG Response with Patronus Percival
Let’s see how Percival helps identify issues in a RAG pipeline and suggests improvements.
Note: The codes in this article are available in this Google Colab notebook.
Install and import the following Python libraries to create a simple RAG application in LangGraph.
!pip install -qU langchain-community
!pip install -qU langchain-openai
!pip install -qU langchain-text-splitters
!pip install -qU langgraph
!pip install -qU langchain-core
!pip install -qU pypdf
!pip install -qU chromadb
!pip install -qU langchain-openai
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langgraph.graph import START, StateGraph
from langchain import hub
from typing_extensions import List, TypedDict
from IPython.display import Image, display
import os
from google.colab import userdata
OPENAI_API_KEY = userdata.get('OPENAI_API_KEY')
We will perform a RAG assessment on a PDF document containing the WHO's global strategy on digital health for 2020-2025. The following script loads the PDF and stores the document chunk in a Chroma vector database.
pdf_url = "https://www.who.int/docs/default-source/documents/gs4dhdaa2a9f352b0445bafbc79ca799dce4d.pdf"
pdf_loader = PyPDFLoader(pdf_url)
docs = pdf_loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
add_start_index=True,
)
doc_splits = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(api_key = OPENAI_API_KEY)
vector_store= Chroma.from_documents(
documents=doc_splits,
embedding=embeddings
)
Next, we will create a LangGraph with `retrieve` and `generate` nodes. The retrieve node retrieves relevant documents from the vector database, while the generate node generates the final response.
prompt = hub.pull("rlm/rag-prompt")
llm = ChatOpenAI(model = 'gpt-4o',
api_key = OPENAI_API_KEY,
)
class State(TypedDict):
question: str
context: List[Document]
answer: str
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
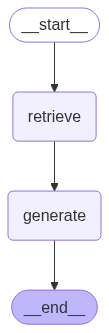
Let’s ask a user questions using the above graph.
input = {"question":"Summarize the global strategy on digital health"}
result = graph.invoke(input)
print(f'Answer: {result["answer"]}')
Here is the output:

Next, we will enable Percival tracing to debug and identify any issues within our RAG pipeline. Install the following libraries:
! pip install patronus
! pip install openinference-instrumentation-langchain
The script below imports the libraries required to debug LangGraph applications with Percival. We also create a Patronus project that groups all your traces for a particular application.
from openinference.instrumentation.langchain import LangChainInstrumentor
PATRONUS_API_KEY = userdata.get('PATRONUS_API_KEY')
patronus.init(
api_key=PATRONUS_API_KEY,
integrations=[
LangChainInstrumentor(),
ThreadingInstrumentor(),
AsyncioInstrumentor(),
],
project_name="rag-demo"
)
Finally, you can use the @patronus.traced() decorator and pass it the trace name to trace the flow of calls in a LangGraph graph.
@patronus.traced("rag_query_flow")
def run_graph(user_query: str):
input = {"question": user_query}
result = graph.invoke(input)
return {result["answer"]}
query = "List three goals for the global strategy on digital health for the year 2025 only? What are the difference between goals of 2024 and goals of 2025?"
result = run_graph(query)
print(result)
To identify the issues in your RAG pipeline, log in to your Patronus dashboard and click `Tracing`. Select the project from the dropdown list at the top and click the trace name (rag_query_flow) from the table below.
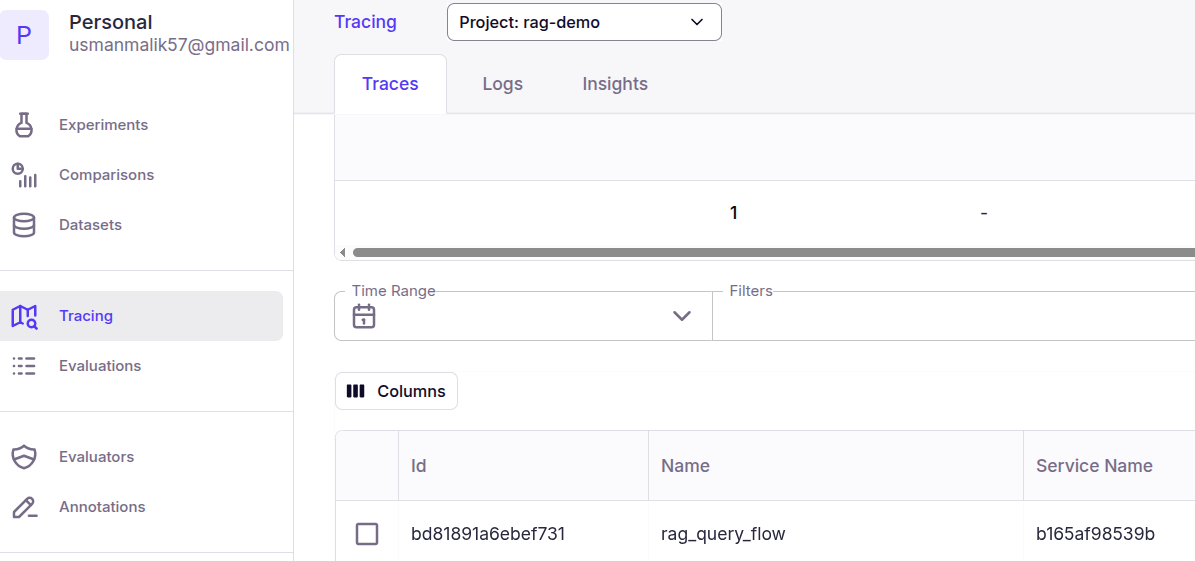
You should see a summary of all the nodes in the graph that the query traversed.
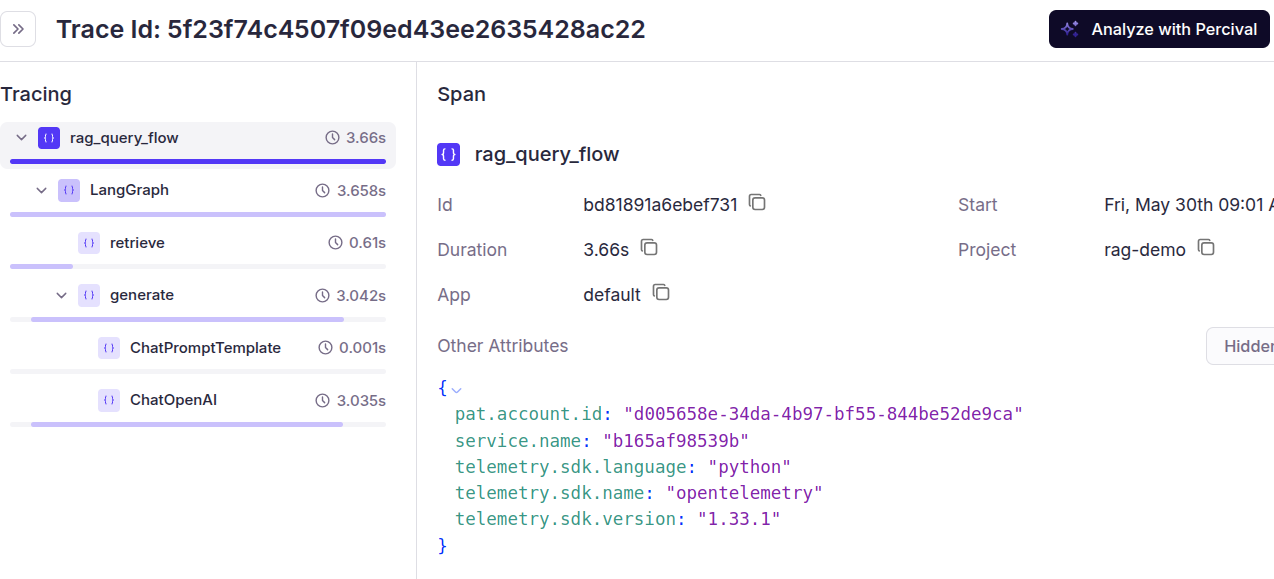
The above output displays all the LangGraph nodes and function calls executed during the RAG process. You can click on a particular step in the above trace and see the input, output, and other details of the tasks executed within a node.
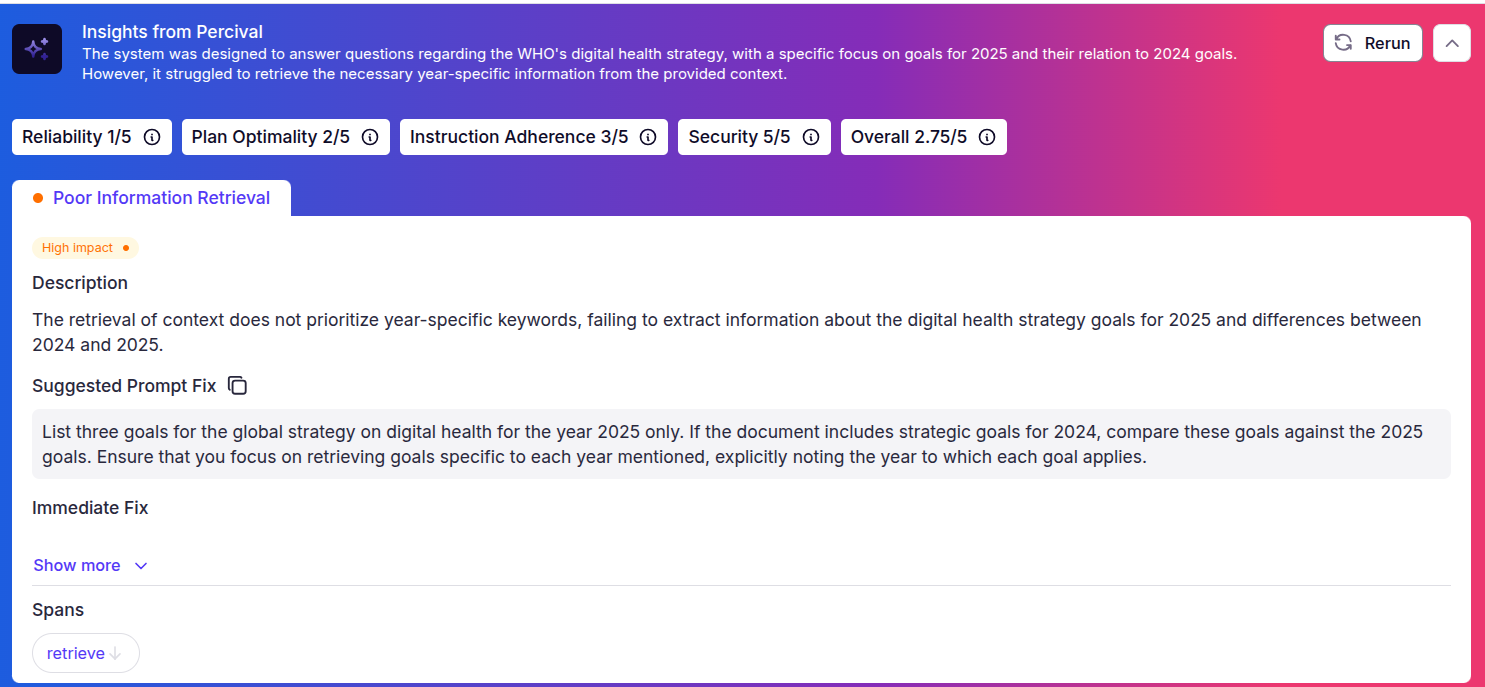
To gain further insights, click the `Analyze with Percival` button on the top right. The following screenshot shows the issues identified by Percival and the suggested prompt fix.
{{banner-dark-small-1="/banners"}}
Final thoughts
We’ve explored a range of AI agent platforms, some geared toward rapid visual building, while others are designed for developers who require complete control. From orchestration logic to debugging tools, the choice ultimately depends on what your team needs and the complexity of the use case.
If you're already working with frameworks like LangChain or CrewAI, or any other agentic framework for that matter, and want a way to keep things reliable, Patronus AI is worth considering. It helps catch broken flows, weird outputs, or just things that don’t feel right.
You can check it out here: Patronus AI